See what Amazon looks for in Data Engineer candidates and check how you measure up.
What strong candidates bring to the role:
Strong candidates bring hands-on experience designing and implementing large-scale batch and streaming data pipelines with clear understanding of Lambda vs Kappa architectural patterns
Strong candidates bring advanced SQL optimization experience and deep understanding of dimensional modeling, schema evolution, and data warehouse design patterns
Strong candidates bring experience building monitoring, alerting, and data quality systems that prevent rather than just detect failures in production data pipelines
Strong candidates bring practical experience with AWS data services and understand the operational trade-offs between different storage and compute options
What Amazon Looks For
Amazon rewards candidates who take ownership beyond their assigned scope and can design for long-term operational excellence. Engineers who thrive here balance moving fast with building systems that won't break at scale, demonstrating the peculiar Amazon culture of high standards combined with customer obsession.
Free — Takes 60 seconds
See your personal gap risk profile
Upload your resume and your target job description. Get your fit score, your top 3 risks, and exactly what to prepare first — before you spend another hour prepping the wrong things.
Data Engineers at Amazon build and maintain the data infrastructure that powers everything from Alexa recommendations to supply chain optimization. Unlike other companies where data engineering is often reactive, Amazon DEs are expected to proactively write technical design documents and get them reviewed by engineering panels before implementation. This emphasis on upfront design reflects Amazon's focus on building systems that scale and last.
What's Different at Amazon
Amazon rewards candidates who take ownership beyond their assigned scope and can design for long-term operational excellence. Engineers who thrive here balance moving fast with building systems that won't break at scale, demonstrating the peculiar Amazon culture of high standards combined with customer obsession.
Technical Design Documentation
Amazon expects Data Engineers to write comprehensive design docs before building systems, similar to engineering RFCs at other companies. Candidates must demonstrate they can think through data architecture decisions, trade-offs, and operational concerns on paper before touching code. This reflects Amazon's written culture and emphasis on thoughtful system design.
Leadership Principles Alignment
Every Amazon interview heavily weights cultural fit through Leadership Principles evaluation. For Data Engineers, Ownership and Operational Excellence carry particular weight since data infrastructure failures cascade across multiple teams. Candidates must show they've taken responsibility for systems beyond their immediate scope.
Data Infrastructure Systems
Amazon's system design questions focus specifically on data platform challenges like Lambda vs Kappa architectures, CDC pipelines, and ML feature stores rather than web-scale APIs. The Bar Raiser tests whether candidates can design data systems that maintain reliability and freshness guarantees at Amazon's scale.
Your Report Adds
Amazon's Leadership Principles are mapped directly to the bullet points on your resume. You'll see exactly which ones you can claim with evidence — and which ones are gaps to address before the interview.
The Amazon Data Engineer interview typically takes 3-4 weeks from application to offer.
Important: Amazon DE system design questions focus on data infrastructure — not web-scale API design. Expect questions about data reliability, freshness guarantees, schema evolution, and ML data pipelines.
1
Phone Screen
45 min
Initial technical screen covering SQL optimization and basic data pipeline concepts, plus one Leadership Principle deep-dive
Evaluates
Core data engineering competency and cultural baseline fit
2
Virtual Technical
45 min
Live coding session focused on PySpark transformations, DataFrame operations, and pipeline algorithms
Evaluates
Hands-on implementation skills with Amazon's preferred data processing frameworks
3
System Design
60 min
Data infrastructure design covering batch vs streaming trade-offs, schema evolution, and operational monitoring
Evaluates
Architectural thinking and ability to design scalable data platforms
4
Bar Raiser Round
60 min
Leadership Principles deep-dive with Amazon's independent cultural assessor, plus technical design documentation exercise
Evaluates
Cultural fitlong-term thinkingand ownership mindset
Round Breakdown — Data Engineer
Sql
17%
Coding
17%
Behavioral Lp
33%
System Design
33%
Your Report Adds
Your report includes a stage-by-stage prep checklist built around your background — what to emphasize in each round, based on the specific gaps between your resume and this role.
At Amazon, every Data Engineer candidate is evaluated against their Leadership Principles. Expand each one below to see what interviewers are actually looking for.
Technical EvaluationAssessed alongside Leadership Principles in every round
Data Pipeline Architecture
Strong candidates bring hands-on experience designing and implementing large-scale batch and streaming data pipelines with clear understanding of Lambda vs Kappa architectural patterns
SQL and Data Modeling
Strong candidates bring advanced SQL optimization experience and deep understanding of dimensional modeling, schema evolution, and data warehouse design patterns
Operational Excellence
Strong candidates bring experience building monitoring, alerting, and data quality systems that prevent rather than just detect failures in production data pipelines
Cloud Data Platforms
Strong candidates bring practical experience with AWS data services and understand the operational trade-offs between different storage and compute options
All Leadership Principles — click any to see how to demonstrate it
At Amazon, Customer Obsession means starting with the customer and working backwards, even when it's technically harder or more expensive. For data engineers, this translates to building data systems that ultimately improve customer experience — faster recommendations, better search results, or more reliable service uptime. Amazon interviewers expect you to connect your technical decisions to customer impact.
How to Demonstrate: Don't just describe technical metrics like latency or throughput — explain how your data pipeline improvements translated to customer benefits. Share examples where you chose a more complex technical solution because it better served customers, even when stakeholders pushed for shortcuts. Demonstrate that you questioned requirements by asking 'how does this help customers?' and influenced design decisions based on customer needs rather than just engineering convenience.
Ownership at Amazon means thinking like an owner who will live with the long-term consequences of technical decisions. For data engineers, this is heavily weighted because poorly designed data systems create years of technical debt. Amazon expects you to consider operational burden, maintenance costs, and scalability from day one, not just whether something works initially.
How to Demonstrate: Describe situations where you advocated for proper data quality monitoring, comprehensive logging, or robust error handling even when it delayed initial delivery. Share examples of returning to fix issues in systems you built months earlier, or proactively improving systems before they broke. Show how you considered the total cost of ownership when choosing between technologies, including factors like team expertise, operational complexity, and future scaling needs.
This principle drives Amazon's preference for building simple, scalable solutions rather than over-engineered systems. For data engineers, it means finding ways to reduce complexity in data architecture while maintaining reliability. Amazon values engineers who can eliminate unnecessary components, reduce data movement, or simplify data models without sacrificing functionality.
How to Demonstrate: Share specific examples where you eliminated unnecessary data transformations, consolidated redundant pipelines, or replaced complex multi-step processes with simpler alternatives. Describe times when you challenged existing architectures and proposed fundamentally different approaches that reduced operational overhead. Show how you balanced simplicity with requirements — avoiding both under-engineering and over-engineering by finding the right level of complexity for the problem at hand.
Amazon interprets this as having strong technical judgment and making good decisions with incomplete information. For data engineers, this often means choosing the right data storage solution, predicting scaling bottlenecks before they happen, or accurately estimating the complexity of data migration projects. The focus is on decision-making quality under uncertainty.
How to Demonstrate: Provide examples where you made crucial technical decisions with limited data and were proven right over time. Describe situations where you predicted system failures or scaling issues before they occurred and took preventive action. Share times when you changed your mind based on new evidence and explain your thought process for weighing trade-offs. Focus on how you gather information, validate assumptions, and make decisions when the path forward isn't obvious.
Amazon values continuous learning because technology evolves rapidly and customer needs change. For data engineers, this means staying current with data technologies, understanding new storage formats, and learning from operational incidents. Amazon expects you to actively seek out learning opportunities rather than waiting for formal training.
How to Demonstrate: Describe how you learned new technologies to solve specific business problems, not just for resume building. Share examples of deep-diving into production issues to understand root causes and applying those learnings to prevent future problems. Show how you've taught yourself about unfamiliar domains when working with new data sources. Explain how you stay informed about industry trends and evaluate which ones are relevant to your work context.
Even as an individual contributor, Amazon expects you to contribute to team growth through mentoring, knowledge sharing, and helping establish hiring standards. For data engineers, this often means creating documentation that helps others learn complex data systems, mentoring junior engineers on data modeling, or contributing to technical interviews.
How to Demonstrate: Share specific examples of mentoring colleagues on data engineering concepts, creating learning resources that others used, or establishing best practices that improved team capabilities. Describe times when you invested extra effort to help teammates grow their technical skills, even when it didn't directly benefit your projects. Show how you've contributed to hiring decisions or helped onboard new team members by sharing your expertise in data systems and tools.
Amazon's high standards focus on sustainable engineering practices that prevent future problems. For data engineers, this means implementing proper data validation, comprehensive monitoring, and robust testing even when deadlines are tight. It's about refusing to accept technical debt that will cause operational issues later.
How to Demonstrate: Provide examples where you pushed back on shortcuts that would have created data quality issues or operational problems. Describe situations where you implemented additional validation or monitoring beyond what was explicitly requested because you knew it was necessary for long-term reliability. Share times when you raised the bar for your team by introducing better practices, tools, or processes that improved overall system quality.
Think Big means designing data systems that can scale far beyond current requirements and considering how your work enables future capabilities. Amazon values engineers who anticipate growth and build foundational systems that support long-term business expansion rather than just solving today's immediate problems.
How to Demonstrate: Describe data architecture decisions you made that proved valuable as the business scaled beyond original expectations. Share examples where you designed systems with future use cases in mind, even when stakeholders only cared about immediate needs. Show how you've thought about data democratization, enabling self-service analytics, or building platforms that multiple teams could leverage. Focus on times when your big-picture thinking prevented major rewrites or enabled new business capabilities.
Bias for Action at Amazon means making progress with imperfect information rather than waiting for complete requirements. For data engineers, this often involves starting with simple data pipelines that can be iterated upon, or implementing quick wins while designing longer-term solutions. Speed matters, but not at the expense of basic reliability.
How to Demonstrate: Share examples where you delivered initial data solutions quickly to unblock stakeholders while simultaneously working on more robust long-term systems. Describe times when you made reasonable assumptions to move forward when requirements were unclear, and how you validated those assumptions. Show how you've broken large data projects into smaller deliverables that provided immediate value while building toward the complete solution.
Frugality in data engineering means optimizing for cost efficiency in storage, compute, and data transfer while maintaining performance requirements. Amazon closely monitors AWS costs and expects engineers to understand the financial impact of their technical decisions. It's about getting maximum value from resources, not just cutting costs arbitrarily.
How to Demonstrate: Provide specific examples where you reduced data storage costs through better compression, partitioning strategies, or lifecycle management without impacting query performance. Describe how you optimized compute costs by right-sizing clusters, improving query efficiency, or scheduling jobs during off-peak hours. Share times when you chose cost-effective solutions that met requirements rather than premium options that provided unnecessary capabilities.
Trust at Amazon is built through reliable delivery, transparent communication about technical challenges, and admitting mistakes quickly. For data engineers, this means being honest about data quality issues, realistic about project timelines, and proactive about communicating when data systems have problems that could impact business decisions.
How to Demonstrate: Share examples where you transparently communicated data quality issues or system limitations to stakeholders, even when it was uncomfortable. Describe times when you admitted mistakes in data pipeline design and took responsibility for fixing them. Show how you've built trust by consistently delivering on commitments, providing accurate estimates, and keeping stakeholders informed about technical risks or dependencies that could affect their work.
Dive Deep means thoroughly investigating technical issues rather than accepting surface-level explanations. For data engineers, this involves understanding why data pipelines fail, analyzing performance bottlenecks at the query level, and identifying root causes of data quality issues. Amazon values engineers who don't stop at 'it works now' but understand why it works.
How to Demonstrate: Provide detailed examples of investigating complex data pipeline failures, including the specific debugging steps you took and tools you used. Describe how you analyzed performance problems by examining query execution plans, resource utilization, or data distribution patterns. Share times when you discovered that the apparent problem was actually a symptom of a deeper architectural issue, and explain how you identified and addressed the root cause.
This principle requires respectfully challenging technical decisions you believe are wrong, then fully supporting the final decision once it's made. For data engineers, this often involves disagreeing with data architecture choices, timeline estimates, or technology selections while providing technical reasoning for your position.
How to Demonstrate: Describe situations where you disagreed with technical approaches proposed by senior engineers or managers, explaining how you presented your concerns and alternative solutions. Share examples where you advocated for different data storage technologies or pipeline architectures based on technical merits. Show how you fully committed to implementing decisions you initially disagreed with, and if possible, how you helped make those decisions successful despite your reservations.
Amazon measures results by business impact, not just technical implementation. For data engineers, this means ensuring that data systems actually enable better business decisions, improved customer experiences, or operational efficiencies. Delivering results includes ongoing operational excellence, not just initial delivery.
How to Demonstrate: Quantify the business impact of data systems you've built — faster decision-making, improved operational efficiency, or enabled new product capabilities. Share examples where you ensured data quality was high enough to trust for important business decisions. Describe how you maintained system reliability over time, including handling unexpected load increases or data source changes. Focus on end-to-end delivery that created lasting business value.
This principle emphasizes creating an inclusive environment where team members can do their best work. For data engineers, this means sharing knowledge about complex data systems, helping colleagues solve technical problems, and contributing to a collaborative team culture where everyone can learn and contribute effectively.
How to Demonstrate: Share examples of how you've made data systems more accessible to colleagues through documentation, training, or tool improvements. Describe times when you helped teammates overcome technical challenges by sharing your expertise or providing mentorship. Show how you've contributed to inclusive team practices, such as ensuring that technical discussions are accessible to people with different experience levels or making data tools easier for non-technical stakeholders to use.
As Amazon grows, individual engineers must consider the broader impact of their technical decisions on society, other teams, and the company's reputation. For data engineers, this means thinking about data privacy, security implications of data access patterns, and ensuring that data systems are robust enough to handle the scale Amazon operates at.
How to Demonstrate: Provide examples where you considered the broader implications of data engineering decisions, such as implementing privacy-preserving techniques or ensuring data access controls met security requirements. Describe how you've designed systems that other teams could safely depend on without creating operational burden. Share times when you proactively addressed potential issues that could have affected multiple teams or customer data, showing awareness of your responsibility beyond just your immediate project scope.
Your Report Adds
Your report scores you against each of these criteria using your resume and the job description — you get a ranked list of where you're strong vs. where you need to build a case before your interview.
Showing 12 questions drawn from 2,600+ reported interviews — ranked by frequency for Amazon Data Engineer candidates.
Your report selects the 12 questions you're most likely to face based on your resume.
Get yours →
Sql2 questions
"Write a SQL query to identify product ASINs that have had decreasing daily order volumes for three consecutive days in the past month, including the percentage drop from the first to third day. The orders table has columns: order_date, asin, quantity_ordered, marketplace_id."
Sql
· Reported 31 times
What they're really asking
This tests your ability to work with Amazon's core business metrics and handle window functions for trend analysis. The interviewer wants to see if you understand retail operations and can write production-quality SQL that scales across millions of ASINs.
What Great Looks Like
Uses LAG() window functions partitioned by ASIN to compare consecutive days, filters for three-day declining patterns, and calculates percentage drops efficiently. Considers edge cases like weekends and handles marketplace segmentation properly.
What Bad Looks Like
Uses self-joins instead of window functions, doesn't handle date gaps correctly, or writes inefficient queries that would timeout on Amazon's data volumes. Ignores the business context of why this metric matters.
"Given Amazon's fulfillment center inventory table, write a query to find items that are overstocked (current inventory > 90 days of projected demand) in one region but understocked (< 7 days demand) in another region within the same country. Include the transfer quantity needed to balance inventory optimally."
Sql
· Reported 27 times
What they're really asking
This evaluates your understanding of Amazon's logistics complexity and inventory optimization algorithms. The interviewer is checking if you can think like an Amazon operations analyst and handle multi-dimensional business constraints in SQL.
What Great Looks Like
Calculates demand forecasts using moving averages, identifies imbalanced regions using CASE statements and window functions, and computes optimal transfer quantities considering shipping costs and safety stock levels.
What Bad Looks Like
Treats this as a simple inventory counting exercise without considering demand patterns, seasonality, or the economics of inter-region transfers. Writes overly complex queries or misses the optimization aspect entirely.
Coding2 questions
"You're processing Amazon's product catalog updates using Spark. Write a PySpark function that takes two DataFrames - current_catalog and incoming_updates - and performs schema evolution when new columns are added to products, while preserving existing data and handling nullable field changes. The function should return both updated catalog and a change log DataFrame."
Coding
· Reported 34 times
What they're really asking
This tests your real-world Spark skills specific to Amazon's evolving product data challenges. The interviewer wants to see how you handle schema drift in production pipelines and maintain data integrity during catalog updates.
"Build a PySpark streaming application that processes Amazon's real-time clickstream data to detect anomalous customer behavior patterns. The stream contains events: timestamp, customer_id, page_type, session_id, action. Implement sliding window logic to flag customers who perform more than 50 actions in any 5-minute window, maintaining state across micro-batches."
Coding
· Reported 29 times
What they're really asking
This evaluates your understanding of stateful stream processing and fraud detection patterns relevant to Amazon's customer protection systems. The interviewer is assessing your ability to handle real-time data processing with memory management constraints.
"Tell me about a time when you had to make a difficult trade-off between data accuracy and delivery timeline for a critical business stakeholder. What was your decision-making process?"
BehavioralCustomer Obsession
· Reported 42 times
What they're really asking
Amazon wants to see how you balance technical perfectionism with business impact. They're evaluating whether you understand that sometimes 80% accuracy delivered on time serves customers better than 99% accuracy delivered late.
"Describe a situation where you identified a significant inefficiency in an existing data pipeline that wasn't part of your assigned responsibilities. How did you approach making improvements?"
BehavioralOwnership
· Reported 38 times
What they're really asking
This probes whether you act like an owner who cares about the entire system's health, not just your assigned tasks. Amazon wants data engineers who proactively identify and fix problems across team boundaries.
"Give me an example of when you had to convince a senior engineer or architect that a simpler data solution was better than their complex proposed approach. What was your strategy?"
BehavioralInvent and Simplify
· Reported 33 times
What they're really asking
Amazon values engineers who can challenge complexity and advocate for simpler solutions, even when facing senior stakeholders. This tests your technical judgment and communication skills in hierarchical situations.
"Tell me about a time when you had to learn a completely new data technology or tool within a tight deadline to solve a critical problem. How did you ensure you were making the right technical decisions despite limited experience?"
BehavioralLearn and Be Curious
· Reported 36 times
What they're really asking
Amazon's technology landscape evolves rapidly, and they need engineers who can quickly master new tools while making sound architectural decisions. This tests your learning velocity and risk management in unfamiliar territory.
"Design a real-time feature store system for Amazon's recommendation engine that needs to serve features for 500 million customers with sub-50ms latency. The system must handle both batch-computed features (purchase history, demographics) and real-time features (current session activity). How would you ensure feature freshness while maintaining performance?"
System Design
· Reported 41 times
What they're really asking
This tests your understanding of Amazon's recommendation infrastructure complexity and the trade-offs between feature freshness, latency, and cost. The interviewer wants to see if you can design systems that balance ML model performance with operational efficiency.
"Amazon's supply chain team needs a data pipeline that processes inventory updates from 200+ fulfillment centers worldwide and provides both real-time inventory views for the website and daily batch reporting for demand planning. How would you architect this considering network partitions and data consistency requirements?"
System Design
· Reported 37 times
What they're really asking
This evaluates your grasp of Amazon's global infrastructure challenges and distributed systems trade-offs. The interviewer is checking if you understand eventual consistency models and can design for both real-time and batch use cases.
"Design a data quality monitoring system for Amazon's customer review pipeline that processes millions of reviews daily. The system needs to detect spam, fake reviews, and data anomalies while providing near real-time alerting to content moderation teams. How would you handle the scale and ensure low false positive rates?"
System Design
· Reported 39 times
What they're really asking
This tests your ability to design ML-powered data quality systems that protect Amazon's review integrity. The interviewer wants to see how you balance automated detection with human oversight and handle the reputation risks of false positives.
"Amazon Web Services customers need a managed data lake service that automatically optimizes storage costs based on access patterns while maintaining query performance. Design a system that can move data between storage tiers (S3 Standard, IA, Glacier) based on usage analytics and customer-defined policies."
System Design
· Reported 35 times
What they're really asking
This assesses your understanding of AWS economics and customer cost optimization needs. The interviewer is evaluating whether you can design systems that automatically balance cost and performance while giving customers control over their data lifecycle policies.
These are the questions Amazon Data Engineer candidates report facing most. Your report takes it further — 12 questions matched to your resume, with what great looks like, red flags to avoid, and which of your experiences to use for each one.
Your report selects 12 questions ranked by likelihood given your specific profile — and for each one, identifies the story from your resume you should tell and the angle most likely to land with Amazon's interviewers.
How to Prepare for the Amazon Data Engineer Interview
A structured prep framework based on how Amazon actually evaluates Data Engineer candidates. Work through these focus areas in order — how much time you spend on each depends on your timeline and starting point.
Phase 1: Understand the Game
Before you prep anything, understand how Amazon actually evaluates you
Learn how Amazon's Leadership Principles work in practice — not as corporate values, but as the actual rubric interviewers use to score you
Understand that two evaluation tracks run simultaneously in every interview: technical depth and Leadership Principles. Most candidates over-index on one
Learn what the Amazon DE expectation process means and how it changes the interview dynamic
Build the technical competency Amazon expects for this role
Practice writing technical design documents for data infrastructure projects, covering architecture decisions, trade-offs, and operational considerations
Master PySpark DataFrame operations, window functions, and streaming transformations that handle late-arriving data and schema evolution
Study Lambda vs Kappa architectures, CDC pipeline design, and the operational trade-offs between batch and real-time processing
Prepare SQL optimization scenarios involving complex joins, partitioning strategies, and query performance tuning at scale
Review AWS data services architecture patterns, especially S3 storage classes, Glue catalog management, and cross-service data flow design
Practice explaining your approach while you solve, not after. Interviewers score your process, not just the answer
Phase 3: Leadership Principles Preparation
Not a separate "behavioral round" — woven into every interview
Leadership Principles questions at Amazon are woven throughout every interview round, with dedicated 15-20 minute behavioral segments plus LP-based follow-ups to technical discussions.
Build 2–3 strong experiences per Leadership Principles principle — not one per principle
Each experience needs a measurable outcome. Quantify impact wherever possible — business results, scale, adoption, or efficiency gains with real numbers
Your experiences must be real and traceable to your actual background. Interviewers probe deeply — vague or fabricated stories fall apart under follow-up questions
Focus first on the most frequently tested principles for this role: Customer Obsession, Ownership, Invent and Simplify
Phase 4: Integration
The phase most candidates skip — and most regret
Practice a 90-minute simulation combining a data pipeline system design question with immediate Leadership Principles follow-ups about ownership and operational decisions you made in past projects.
Practice out loud, timed, from start to finish. Silent practice does not prepare you for the pressure of speaking under scrutiny
Identify your weakest Leadership Principles area and your weakest technical area. Spend disproportionate final-week time there — interviewers will probe your gaps
Do a full dry-run 2–3 days before your interview. Not the day before — you need time to course-correct
Amazon-Specific Tip
Amazon rewards candidates who take ownership beyond their assigned scope and can design for long-term operational excellence. Engineers who thrive here balance moving fast with building systems that won't break at scale, demonstrating the peculiar Amazon culture of high standards combined with customer obsession.
Watch Out For This
“Tell me about a production incident that was your fault. What happened and what did you change?”
Tests Ownership and Dive Deep — Amazon wants DEs who learn from production failures, not hide from them
Your report includes the full answer framework for this question and Amazon's other curveball questions — mapped to your specific background.
This plan works for any Amazon Data Engineer candidate.
Your report makes it specific to you — the exact gaps in your background, the exact questions your resume makes likely, and a clear picture of exactly what to focus on given your specific risks.
Your report includes 8 stories pre-drafted from your resume, each mapped to a specific Amazon Leadership Principles and competency. You practice answers — you don't write them from scratch the week before your interview.
You've worked too hard for your resume to fail the Amazon DE interview. Walk in knowing your 3 biggest red flags — and exactly what to say when they surface.
Not hoping you prepared the right things. Knowing.
Your report starts with your resume, scores you against this exact role, and tells you which Leadership Principles you can prove with evidence — and which ones Amazon will probe. Then it shows you exactly what to do about the gaps before they find them. Your STAR stories are pre-drafted from your own experience. Your gap scripts are written for your specific vulnerabilities. Nothing generic.
This Page — Free Guide
✓ What Amazon looks for in any DE
✓ Most likely questions from reported interviews
✓ General prep framework
🔒 How your background measures up
🔒 Your 12 specific questions
🔒 Scripts for your gaps
→
Your Report — Personalized
✓ Your 3 biggest red flags — identified by name
✓ Exact bridge scripts for each gap
✓ Your STAR stories pre-drafted from your resume
✓ Question types most likely for your background
✓ Your experiences mapped to Leadership Principles
✓ Your fit score against this exact role
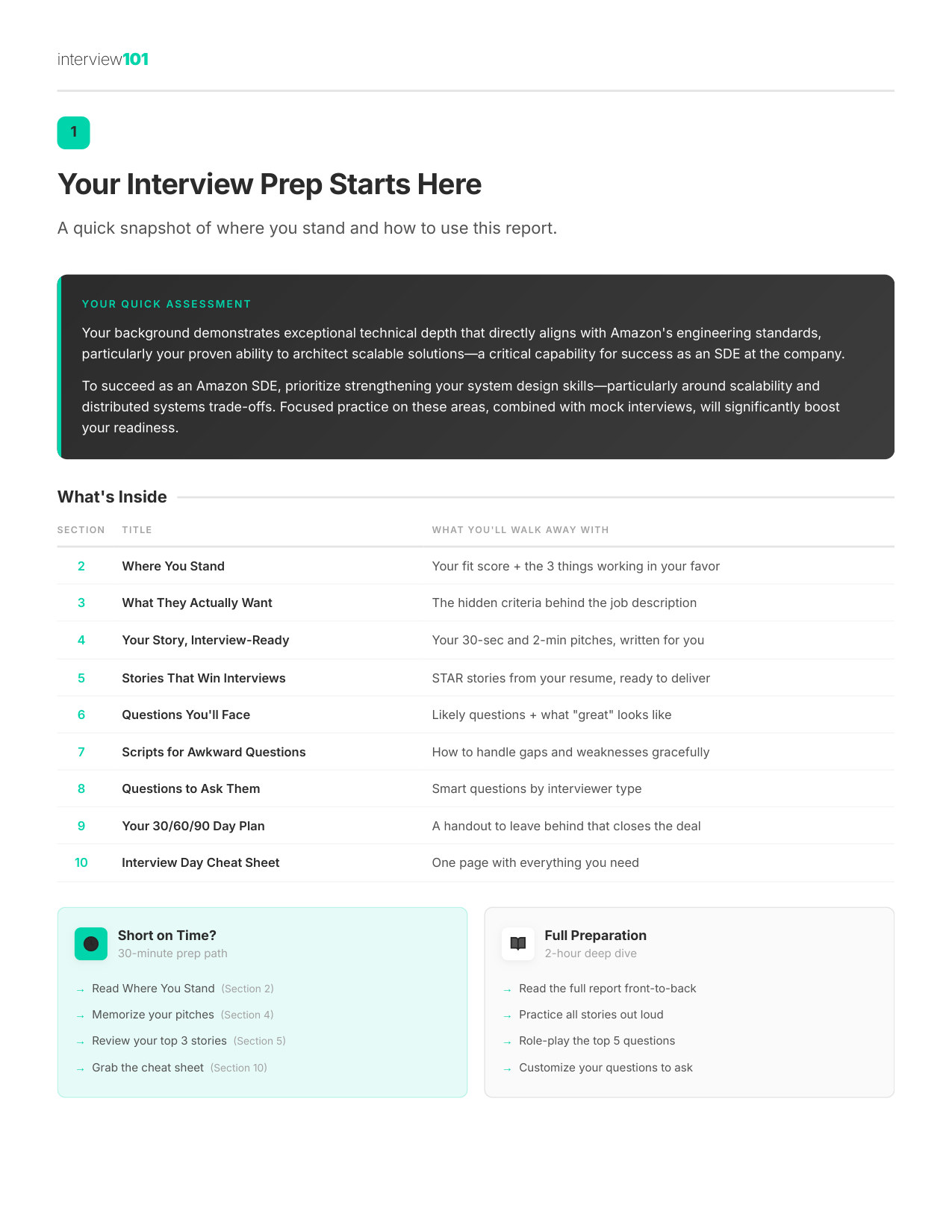
What's Inside Your 55-Page Report
1
Orientation
The unspoken bar Amazon sets — what most candidates miss before they even walk in
2
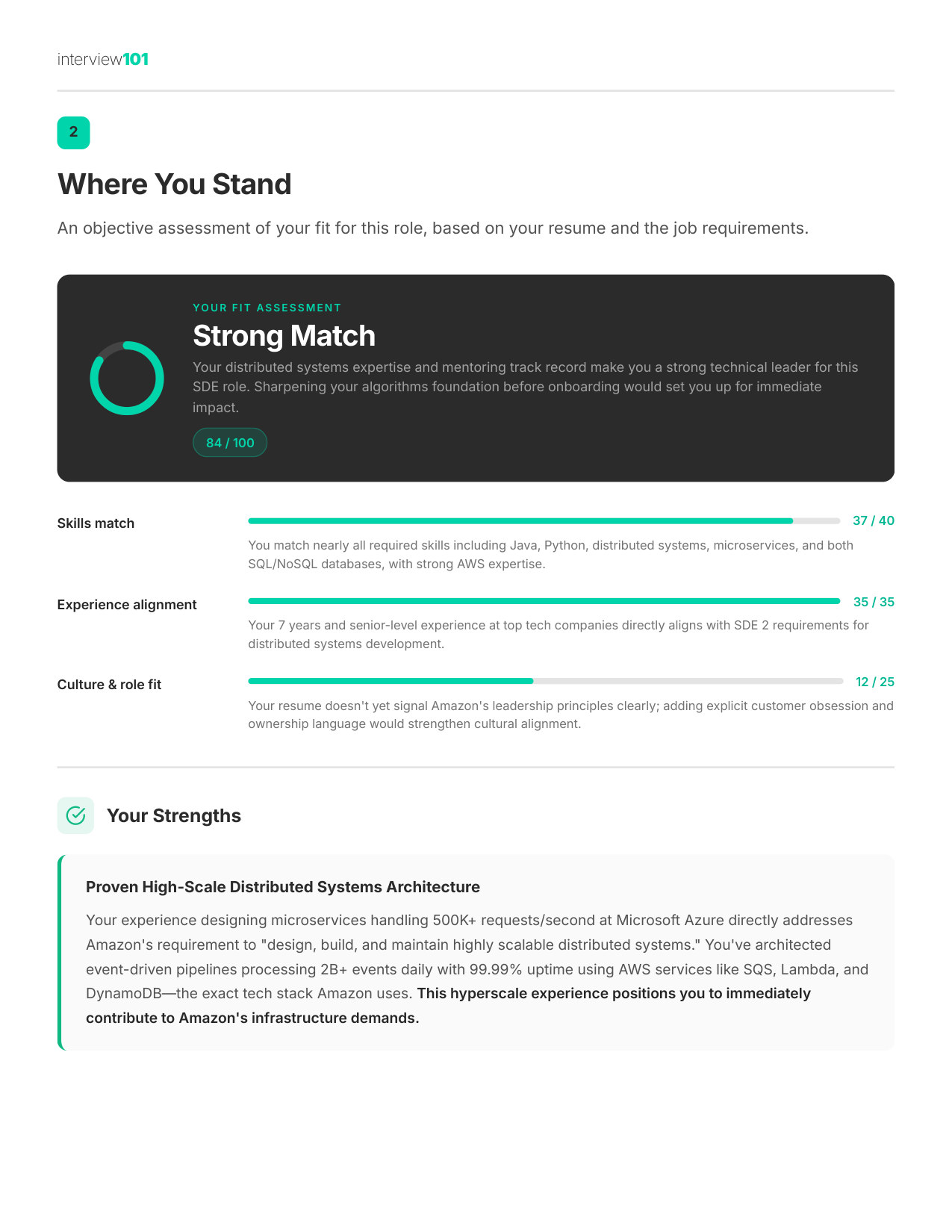
Where You Stand
Your fit score by skill, experience, and culture fit — know your strengths before they probe your gaps
3
What They Actually Want
The real criteria interviewers score you on — beyond what the job description says
4
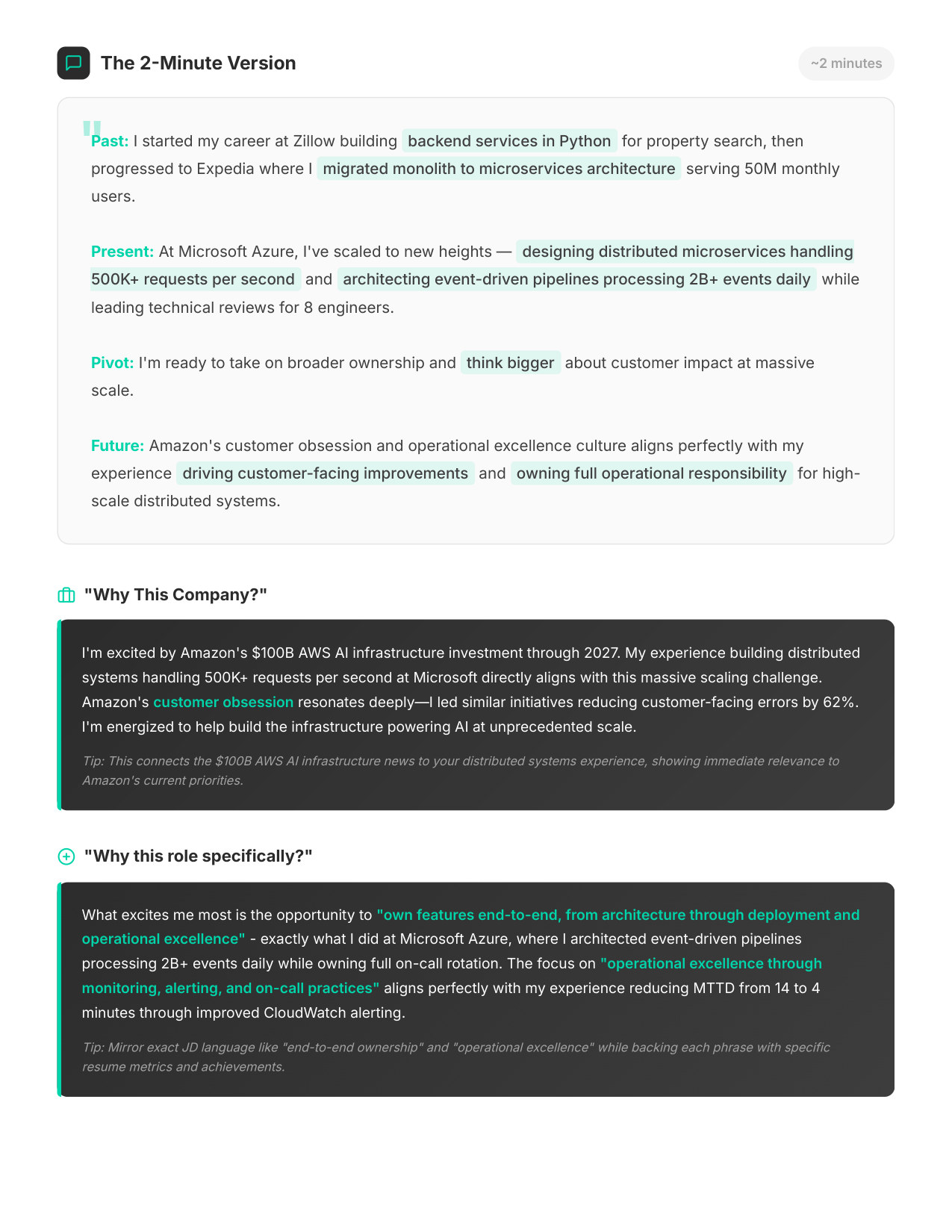
Your Story
Your resume reframed for Amazon's lens — how to position your background so it lands
5
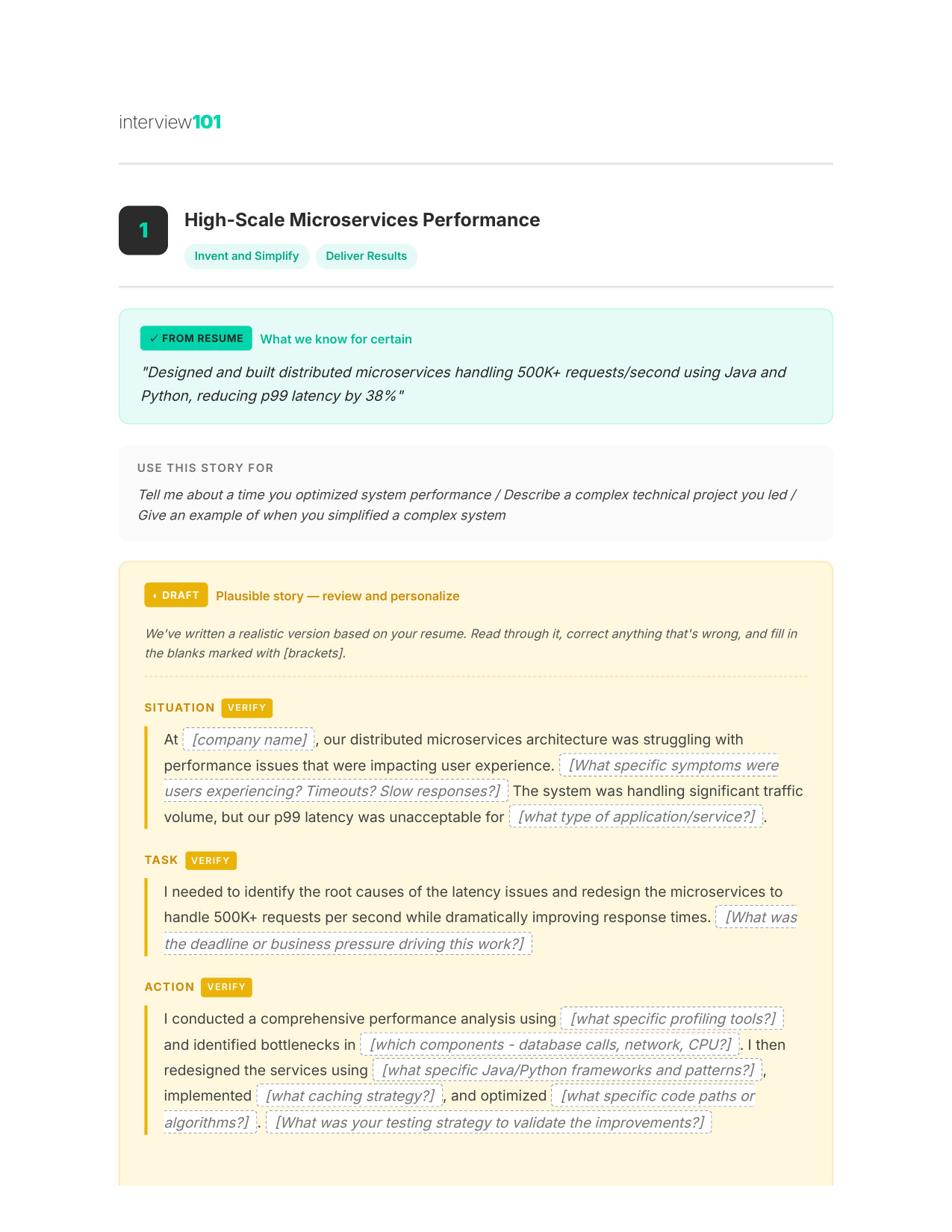
Experience That Wins
Your specific experiences mapped to the Leadership Principles you'll face — walk in knowing which examples to use
6
Questions You Will Face
The question types most likely given your background — with what a strong answer looks like for someone in your position
7
Scripts for Awkward Questions
Exact words for when they probe your weakest areas — so you do not freeze when it matters most
8
Questions to Ask Them
Sharp questions that signal preparation and seniority — and make interviewers remember you
9
30/60/90 Day Plan
Show Amazon you're already thinking like an employee — demonstrates ownership from day one
10
Interview Day Cheat Sheet
One page. Everything you need. Review 5 minutes before you walk in — and walk in ready.
How It Works
1
Upload your resume + target JD
The job description you're actually applying to — not a generic one
2
We analyze your fit
Your background is scored against the Amazon DE blueprint — gaps, strengths, likely questions
3
Your report arrives within 24 hours
55-page personalized PDF delivered to your inbox — ready to work through before your interview
See Inside the Report
Real pages from a Amazon Software Engineer report
Your DE report follows the same structure — built entirely around your background and this role.
1 / 11Your Interview Prep Starts Here
Zoom
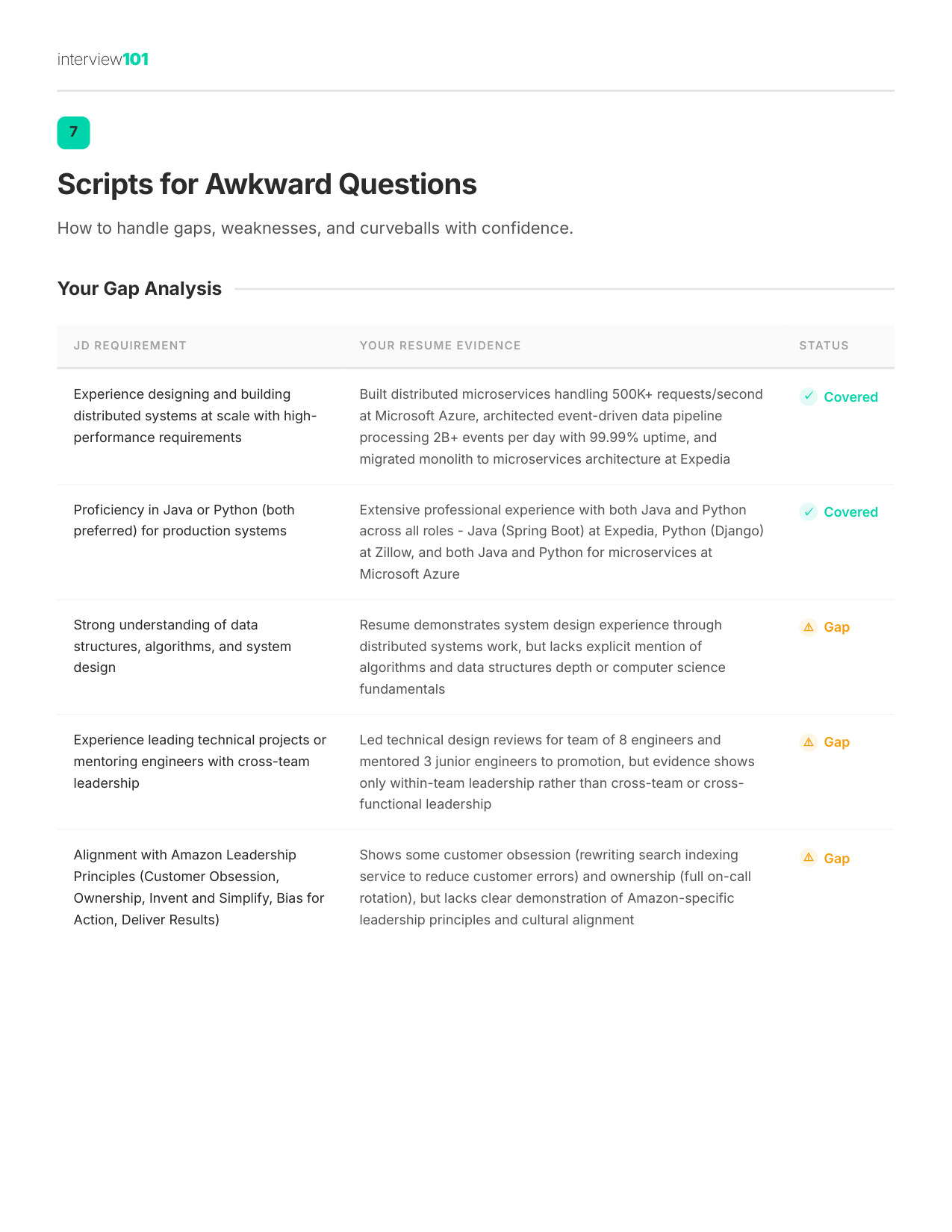
2 / 11Where You Stand
Zoom
3 / 11What They Actually Want
Zoom
4 / 11Your 2-Minute Pitch
Zoom
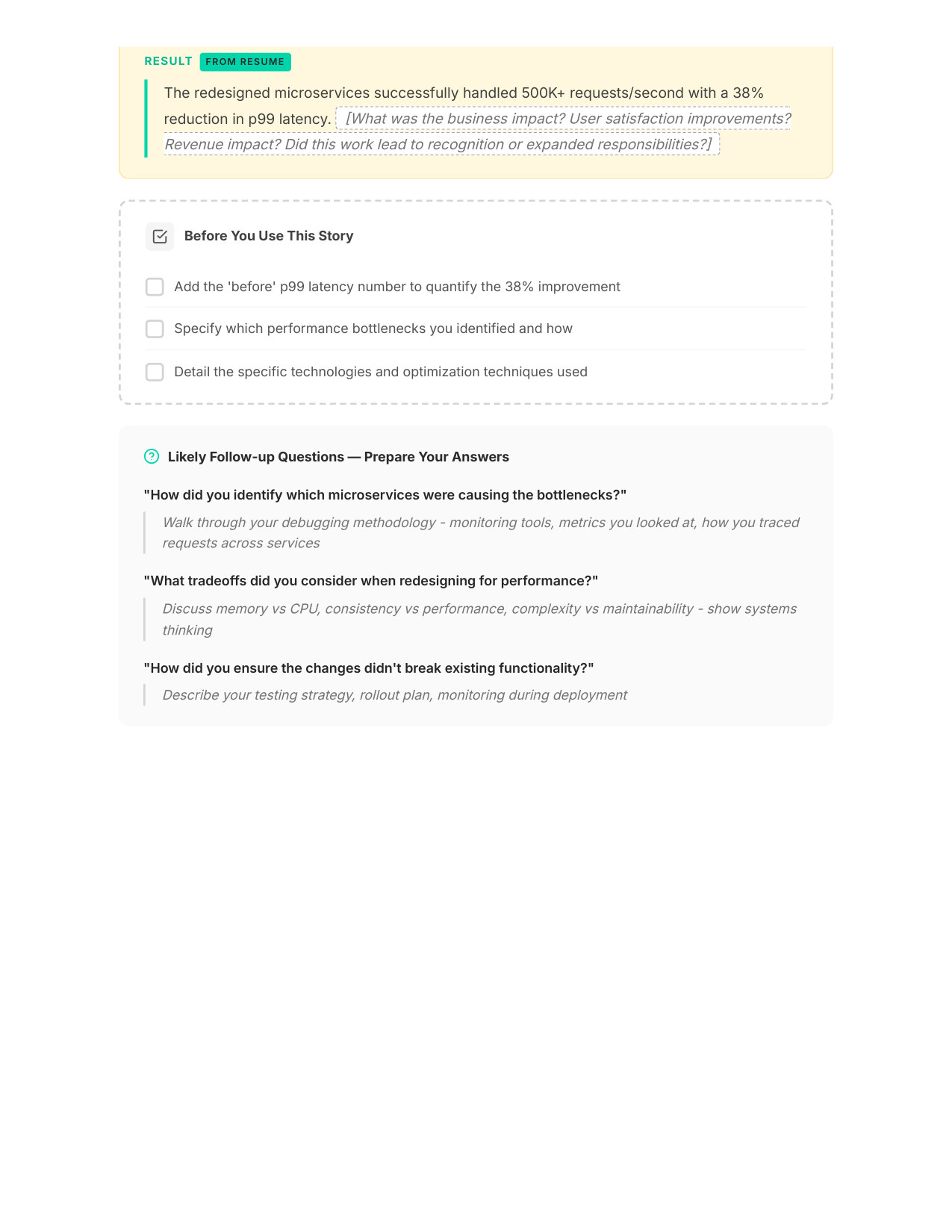
5 / 11Your STAR Story (Page 1)
Zoom
6 / 11Your STAR Story (Page 2)
Zoom
7 / 11Questions You'll Face
Zoom
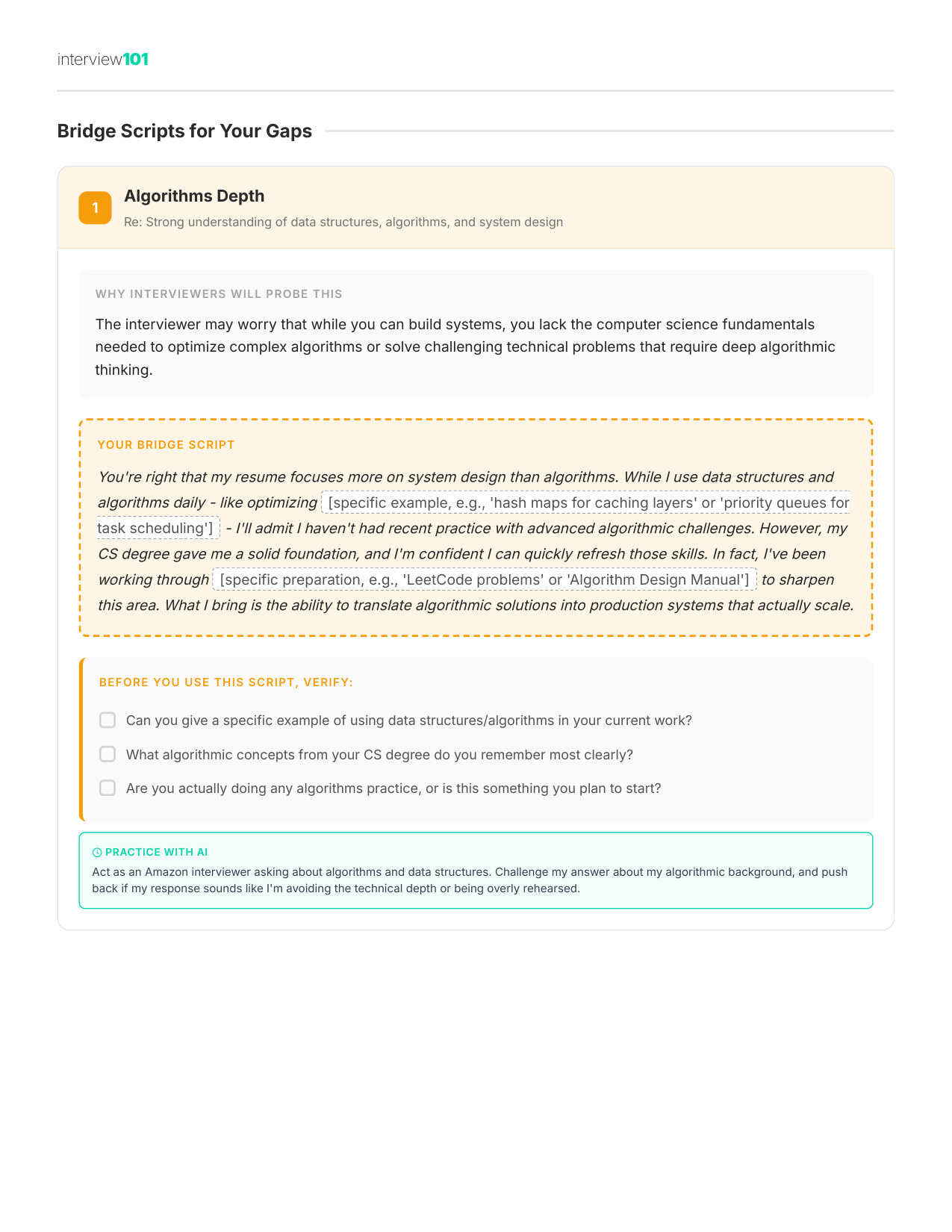
8 / 11Scripts for Awkward Questions
Zoom
9 / 11Your Gap Script
Zoom
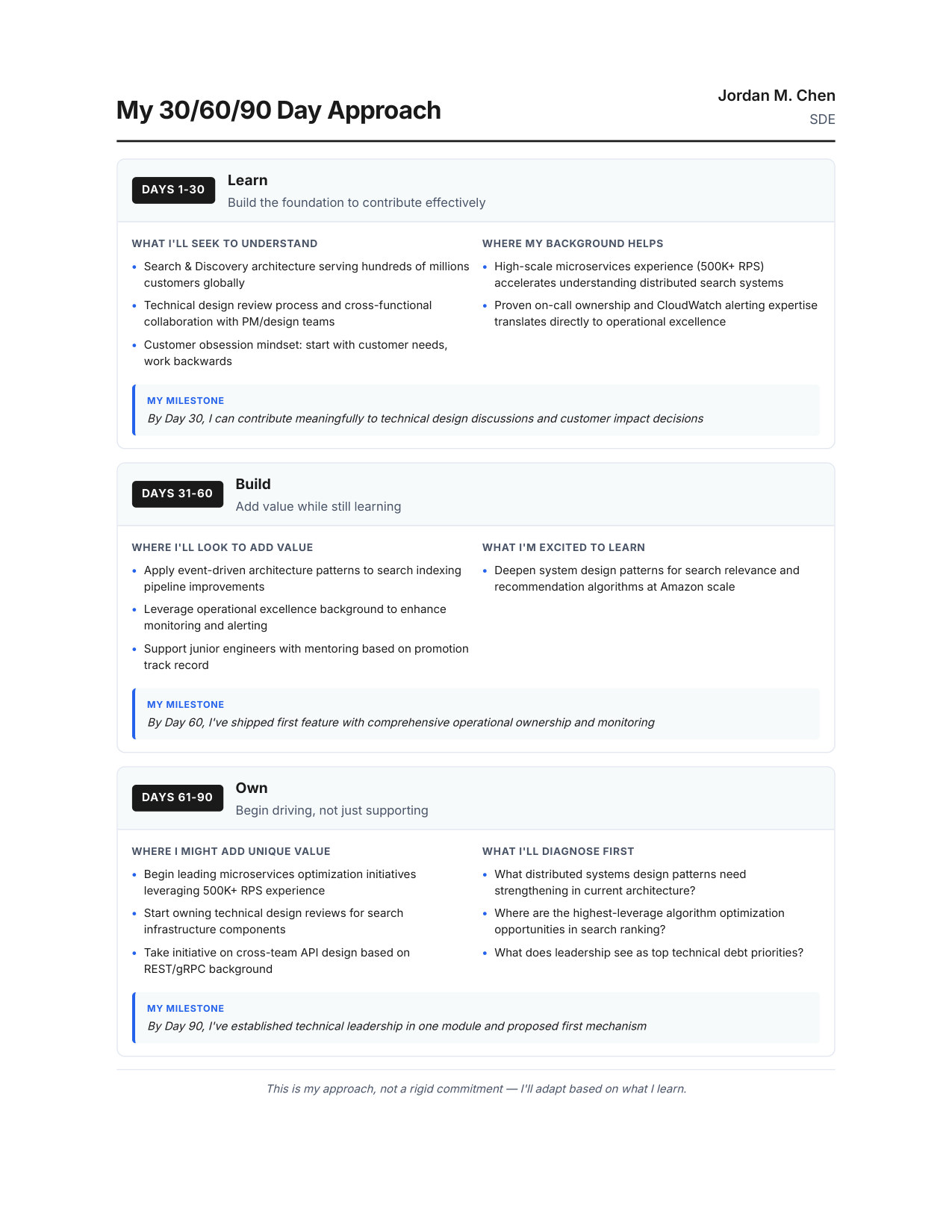
10 / 1130/60/90 Day Plan
Zoom
11 / 11Interview Day Cheat Sheet
Zoom
Download the Full Sample Report — Free
See exactly what you're buying before you commit — 50+ pages, no email required
🔒 30-day money-back guarantee — no questions asked
FAQ
Common Questions About the Amazon Data Engineer Interview
The Amazon Data Engineer interview process typically takes 3-4 weeks from application to offer. This timeline includes initial screening, scheduling, completing all interview rounds, and final decision-making.
Amazon's Data Engineer interview consists of 4 rounds: a 45-minute Phone Screen, a 45-minute Virtual Technical round, a 60-minute System Design round, and a 60-minute Bar Raiser Round. Each round combines technical questions with Amazon's Leadership Principles assessment.
Focus heavily on Amazon's Leadership Principles, as they're assessed in every single interview round alongside technical questions. Additionally, prepare for data infrastructure system design questions covering data reliability, freshness guarantees, schema evolution, and ML data pipelines rather than web-scale API design.
You must wait 6 months after rejection before reapplying to Amazon for any role. Use this time to strengthen areas where you received feedback and gain more experience with the Leadership Principles and data engineering systems.
Yes, Amazon assesses Leadership Principles through behavioral questions in every interview round alongside technical questions. There aren't separate dedicated behavioral rounds - instead, Leadership Principles evaluation is woven throughout the entire interview process.
Amazon Data Engineer coding focuses on data engineering-specific problems: Spark transformations, PySpark DataFrame operations, pipeline algorithms with window functions, stateful processing, and schema evolution. You won't encounter generic data structure problems like binary tree traversal or graph algorithms.
This page shows you what the Amazon Data Engineer interview looks like in general. Your personalized report shows you how to prepare specifically — using your resume, a real job description, and Amazon's actual evaluation criteria.
This page shows every Amazon DE candidate the same thing. Your report is built around you — your resume, your gaps, your most likely questions.
What's inside: your fit score broken down by skill, experience, and culture; your top 3 risk areas by name; the 12 questions most likely for your specific background with full answer decodes; your experiences mapped to the Leadership Principles you'll face; scripts for when they probe your weakest spots; sharp questions to ask your interviewers; and a one-page cheat sheet to review before you walk in. 55 pages. Delivered within 24 hours.
Within 24 hours. Your report is reviewed and delivered to your inbox within 24 hours of payment. Most orders arrive significantly faster. You'll receive an email with your personalized PDF as soon as it's ready.
30-day money-back guarantee, no questions asked. If your report doesn't help you feel more prepared, email us and we'll refund in full.