See what Meta looks for in Data Engineer candidates and check how you measure up.
What strong candidates bring to the role:
Advanced Presto/Spark SQL including window functions, CTEs, self-joins, and complex analytical queries on petabyte-scale event tables. Must demonstrate both correctness and efficiency.
Pandas DataFrame manipulation, dictionary operations, list processing, and string handling for data transformation tasks. Not algorithm and data structure problems.
Star schema design for social platform analytics, slowly changing dimensions for user attributes, and bridge tables for complex relationships. Must scale to billions of users.
Converting product goals into metric definitions, schema design, and ETL logic. Requires understanding both business context and technical implementation.
What Meta Looks For
Meta evaluates product sense as a first-class requirement alongside SQL and data modeling, requiring you to translate business goals into technical data solutions in real-time.
Free — Takes 60 seconds
See your personal gap risk profile
Upload your resume and your target job description. Get your fit score, your top 3 risks, and exactly what to prepare first — before you spend another hour prepping the wrong things.
Meta Data Engineers sit within the Product Analytics organization, making them product-minded infrastructure builders rather than pure pipeline engineers. You'll translate product goals like "measure Instagram Stories engagement" into data architecture decisions, metric definitions, and ETL pipelines. This product-first approach means you need both technical depth in SQL/Python and the ability to think like a product analyst.
What's Different at Meta
Meta evaluates product sense as a first-class requirement alongside SQL and data modeling, requiring you to translate business goals into technical data solutions in real-time.
Product-Driven Data Architecture
You'll receive a product goal and must define success metrics, design the schema, and write the ETL SQL in one continuous exercise. This tests your ability to think like both a product analyst and a data engineer, translating business requirements into scalable data solutions.
Speed and SQL Mastery
The technical screen requires passing 3 of 5 SQL questions and 3 of 5 Python questions within 60 minutes on CoderPad. Meta evaluates efficiency and correctness under time pressure, testing your fluency with Presto/Spark SQL, window functions, and pandas data manipulation.
Ownership-Driven Impact
Meta expects Data Engineers to drive projects independently and enable product decisions through data infrastructure. Your behavioral stories must demonstrate navigating ambiguity, proactively unblocking teams, and building scalable solutions that impact users at social-platform scale.
Your Report Adds
Meta's Meta Core Values are mapped directly to the bullet points on your resume. You'll see exactly which ones you can claim with evidence — and which ones are gaps to address before the interview.
The Meta Data Engineer interview typically takes 3-5 weeks from application to offer.
Important: Meta DE interviews have a unique technical screen format: 5 SQL questions + 5 Python questions in 1 hour on CoderPad. You need to pass at least 3 of 5 in each category to advance — speed and efficiency are the primary signals, not just correctness. The onsite loop (4-5 rounds) includes an Advanced SQL/Coding round, a Data Modeling round (Kimball fundamentals, star schema, SCDs), a Product Sense/Full-Stack round (the hardest — product goal to metric to schema to ETL SQL in one exercise), and a Behavioral/Ownership round. Python questions are data manipulation focused — pandas, dictionaries, list operations — NOT algorithm practice DSA.
1
Technical Screen
60 min
5 SQL questions plus 5 Python questions on CoderPad. Must pass 3 of 5 in each category to advance. Focuses on speed and efficiency, not just correctness.
Evaluates
SQL fluency with window functions and complex joinsPython data manipulation with pandas
2
Advanced SQL/Coding
45-60 min
Complex SQL problems involving funnel analysis, cohort retention, and time-series aggregations on social platform event data. Some Python data processing problems.
Design star schema for user behavior events, handle slowly changing dimensions, create bridge tables for many-to-many relationships like user-group memberships.
Given a product goal, define metrics, design schema, and implement ETL SQL. The most challenging round that mirrors real Meta DE work combining product and technical skills.
Evaluates
Product intuitionmetric definitionend-to-end data pipeline design
5
Behavioral/Ownership
45 min
Meta Core Values questions focused on driving data projects independently, enabling partner teams, and building scalable infrastructure under ambiguity.
Evaluates
Leadership through influencecross-team collaborationlong-term thinking
Round Breakdown — Data Engineer
Sql
25%
Python Data
17%
Data Modeling
25%
Behavioral Ownership
17%
Product Sense Fullstack
17%
Your Report Adds
Your report includes a stage-by-stage prep checklist built around your background — what to emphasize in each round, based on the specific gaps between your resume and this role.
At Meta, every Data Engineer candidate is evaluated against their Meta Core Values. Expand each one below to see what interviewers are actually looking for.
Technical EvaluationAssessed alongside Meta Core Values in every round
SQL Mastery
Advanced Presto/Spark SQL including window functions, CTEs, self-joins, and complex analytical queries on petabyte-scale event tables. Must demonstrate both correctness and efficiency.
Python Data Processing
Pandas DataFrame manipulation, dictionary operations, list processing, and string handling for data transformation tasks. Not algorithm and data structure problems.
Data Modeling Design
Star schema design for social platform analytics, slowly changing dimensions for user attributes, and bridge tables for complex relationships. Must scale to billions of users.
Product-to-Pipeline Translation
Converting product goals into metric definitions, schema design, and ETL logic. Requires understanding both business context and technical implementation.
All Meta Core Values — click any to see how to demonstrate it
At Meta, this means prioritizing speed of iteration and learning over perfect upfront planning. Meta interviewers expect you to demonstrate comfort with building data solutions when requirements are evolving or incomplete, shipping something functional quickly, and then iterating based on feedback. This is central to Meta's product development culture where data needs change rapidly as products evolve.
How to Demonstrate: Show specific examples where you made deliberate trade-offs to ship faster — like choosing a simpler data model that could be extended later, or building a pipeline with basic monitoring first and adding sophisticated alerting in iteration two. Emphasize the decision-making process: what you chose to deprioritize, how you communicated the trade-offs to stakeholders, and how the early delivery enabled faster learning. Meta interviewers want to see you can distinguish between 'good enough for now' and 'shipped garbage' — demonstrating thoughtful shortcuts rather than careless rushing.
Meta values data engineers who question established patterns when they see opportunities for significant improvement. This means having the technical judgment to identify when current approaches are suboptimal and the conviction to advocate for better solutions, even when it means challenging senior stakeholders or established team practices. Meta's culture rewards calculated risks that drive meaningful improvements.
How to Demonstrate: Present examples where you identified fundamental flaws in existing data approaches — like proposing a completely different dimensional model that better reflected user behavior, or advocating for real-time processing where batch was causing product decisions to lag. Focus on how you built the case: the data you gathered, how you quantified the impact of the current approach's limitations, and how you navigated stakeholder concerns. Meta interviewers look for candidates who can balance boldness with pragmatism — showing you didn't just critique but delivered a working alternative that proved the value of your approach.
Meta operates at a scale where short-sighted data decisions create massive technical debt, so they prioritize engineers who think beyond immediate deliverables. This means designing data architecture that can evolve with changing product needs, building pipelines that can handle 10x growth without complete rewrites, and creating data models that enable future analytics use cases even if they're not currently required.
How to Demonstrate: Describe specific architectural decisions where you chose more complex upfront implementation to avoid future scaling problems — like designing a flexible event schema that could accommodate new product features, or building a pipeline architecture that separated ingestion from transformation to enable independent scaling. Quantify the long-term payoff: how much rework you prevented, how easily the system adapted to new requirements, or how other teams were able to build on your foundation. Meta interviewers want to see you can balance current delivery pressure with architectural foresight, not just theoretical future-proofing.
Meta's culture emphasizes radical transparency and proactive collaboration, especially important for data engineers whose work often becomes foundational for multiple teams. This means actively sharing your work, insights, and learnings beyond your immediate stakeholders, and creating documentation or tools that help others succeed without requiring your direct involvement. It's about making data more accessible across the organization.
How to Demonstrate: Give concrete examples of going beyond your assigned deliverables to help the broader organization — like creating self-service documentation that eliminated repetitive requests, sharing analysis that revealed insights useful to adjacent teams, or building data tools that other engineers could leverage for their own projects. Emphasize the multiplier effect: how your proactive sharing enabled others to work more efficiently or make better decisions. Meta interviewers look for candidates who see knowledge sharing as part of their core responsibility, not an extra task, and can demonstrate measurable impact from this approach.
Meta expects data engineers to connect their technical work to user outcomes and understand how data infrastructure decisions ripple through to billions of users. This means thinking beyond just building functional pipelines to considering how your data enables product teams to create better user experiences, improve safety, or drive meaningful social connections. The scale amplifies both positive impact and potential harm.
How to Demonstrate: Describe projects where your data work directly influenced product decisions that improved user experiences — like building measurement frameworks that helped product teams optimize for meaningful engagement rather than just time spent, or creating data models that enabled better content ranking to surface more valuable posts. Focus on the connection between technical choices and user outcomes: how your schema design enabled faster experimentation, how your pipeline reliability prevented user-facing feature degradation, or how your metric definitions helped teams make decisions that improved user satisfaction. Meta interviewers want to see you understand that data infrastructure isn't just about moving bits — it's about enabling better products for real people.
Your Report Adds
Your report scores you against each of these criteria using your resume and the job description — you get a ranked list of where you're strong vs. where you need to build a case before your interview.
Showing 12 questions drawn from 2,600+ reported interviews — ranked by frequency for Meta Data Engineer candidates.
Your report selects the 12 questions you're most likely to face based on your resume.
Get yours →
Sql3 questions
"We have a Presto table `instagram_stories_events` with columns (user_id, story_id, event_type, timestamp, country). Write a query to calculate the 7-day rolling retention rate for users who posted their first story in the past month, segmented by country. Include only countries with at least 1000 first-time story posters."
Sql
· Reported 31 times
What they're really asking
This tests your ability to handle complex time-series analysis with window functions and self-joins on petabyte-scale event data. The interviewer is evaluating whether you understand cohort analysis patterns that Meta uses for product metrics, and if you can optimize queries for Presto's distributed execution.
What Great Looks Like
Uses CTEs to first identify first-time story posters, then employs window functions with proper date arithmetic to calculate rolling retention. Demonstrates understanding of Presto performance by using appropriate partitioning and avoiding unnecessary self-joins.
What Bad Looks Like
Writes nested subqueries that would timeout on large datasets, mishandles date calculations for rolling windows, or fails to properly segment the cohort analysis by country with the minimum threshold.
"Given a Facebook posts table with (post_id, user_id, created_time, post_type) and an engagement table with (post_id, user_id, action_type, timestamp), write a query to find posts that had their peak engagement rate in the first hour but then dropped below 10% of that peak in the subsequent 23 hours."
Sql
· Reported 27 times
What they're really asking
This tests advanced window function usage with LAG/LEAD and time-based partitioning that mirrors Meta's real-time engagement monitoring. The interviewer wants to see if you can translate complex product requirements into efficient SQL that works on streaming data pipelines.
What Great Looks Like
Uses window functions with time-based partitioning to calculate hourly engagement rates, then employs LAG/LEAD to compare peak vs. subsequent periods. Shows awareness of how this query would integrate with Meta's real-time analytics infrastructure.
What Bad Looks Like
Over-complicates with multiple self-joins instead of window functions, doesn't properly handle the time-based comparison logic, or writes a solution that couldn't scale to billions of posts per day.
"Write a query using our WhatsApp messages fact table to identify user cohorts who sent their first message in Q1 2024 and calculate their monthly message volume progression through Q3 2024, including the percentage of users who became 'power users' (100+ messages/month) by their 6th month."
Sql
· Reported 25 times
What they're really asking
This evaluates your understanding of slowly changing dimensions and cohort tracking across Meta's messaging platforms. The interviewer is testing whether you can design queries that support product team decisions about user lifecycle and growth patterns at WhatsApp's scale.
"You have a pandas DataFrame with columns ['user_id', 'session_start', 'pages_viewed', 'country'] representing user sessions. Write Python code to create a summary that shows, for each country, the distribution of session lengths (in quartiles) and identify users who have sessions in the top 5% of page views but bottom 25% of session duration."
Python Data
· Reported 29 times
What they're really asking
This tests practical pandas operations that data engineers use daily at Meta for ad-hoc analysis and data quality checks. The interviewer is evaluating your fluency with DataFrame operations and whether you can translate product analytics requirements into efficient Python code.
"Given a dictionary where keys are Facebook page IDs and values are lists of daily impression counts for the past 30 days, write Python code to identify pages that show a statistically significant upward trend in impressions and return them ranked by the strength of the trend."
Python Data
· Reported 24 times
What they're really asking
This tests your ability to implement statistical analysis in Python for trend detection, which is core to Meta's content performance monitoring. The interviewer wants to see if you can work with nested data structures and implement algorithms that inform product decisions about content reach.
"Design a star schema to track Instagram Reels performance metrics across different recommendation algorithms. Include fact tables for user interactions (views, likes, shares, comments) and dimension tables for content metadata, user segments, and algorithm variants. How would you handle the slowly changing dimension of algorithm parameters?"
Data Modeling
· Reported 33 times
What they're really asking
This tests your understanding of Kimball methodology applied to Meta's recommendation systems and A/B testing infrastructure. The interviewer is evaluating whether you can design schemas that support both real-time personalization and historical analysis for algorithm performance measurement.
"Meta wants to build a unified data model for cross-platform user behavior analysis (Facebook, Instagram, WhatsApp). Design a schema that can track user actions across platforms while preserving platform-specific attributes and handling users who don't have accounts on all platforms."
Data Modeling
· Reported 28 times
What they're really asking
This evaluates your ability to design complex data models that support Meta's family of apps strategy while handling data governance and privacy constraints. The interviewer is testing whether you understand identity resolution and cross-platform analytics at social media scale.
"Design an event-driven data model for Meta's advertising auction system that can support both real-time bid optimization and historical campaign performance analysis. Include how you'd handle the high-frequency auction events while enabling time-travel queries for advertiser reporting."
Data Modeling
· Reported 26 times
What they're really asking
This tests your understanding of streaming data architecture and temporal data modeling for Meta's core revenue engine. The interviewer wants to see if you can balance real-time performance requirements with analytical needs for advertiser-facing reporting systems.
"Tell me about a time when you had to move fast to deliver a data pipeline or schema change under ambiguous requirements. How did you balance speed with data quality, and what would you do differently?"
Behavioral OwnershipMove Fast
· Reported 35 times
What they're really asking
This tests whether you can operate effectively in Meta's fast-paced environment where product requirements change rapidly and perfect specifications aren't always available. The interviewer wants to see if you can make pragmatic engineering decisions that unblock product teams while maintaining data integrity.
"Describe a situation where you proposed a data architecture or metric definition that challenged the existing approach and delivered better outcomes. How did you build consensus and measure success?"
Behavioral OwnershipBe Bold
· Reported 30 times
What they're really asking
This evaluates your willingness to challenge technical status quo and drive architectural improvements that enable better product decisions. The interviewer wants to see if you can lead technical discussions and influence cross-functional stakeholders even when proposing significant changes.
"Meta wants to launch a feature that shows users 'memory highlights' from their activity one year ago. Walk me through how you would define success metrics, design the data schema to support this feature, and write the ETL logic to identify meaningful highlights for users."
Product Sense Fullstack
· Reported 32 times
What they're really asking
This tests your ability to translate product vision into concrete data infrastructure while understanding user behavior patterns at Meta's scale. The interviewer is evaluating whether you can think like a product engineer and design systems that directly enable user-facing features with appropriate success measurement.
"Facebook Groups wants to measure and improve community health. Design the end-to-end data infrastructure from event collection to dashboard metrics that would help product managers understand which groups are thriving vs. declining, and recommend data-driven interventions."
Product Sense Fullstack
· Reported 27 times
What they're really asking
This evaluates your ability to design comprehensive analytics systems that support complex product decisions about community dynamics. The interviewer wants to see if you understand how data infrastructure enables content moderation, community growth strategies, and product feature prioritization at social platform scale.
These are the questions Meta Data Engineer candidates report facing most. Your report takes it further — 12 questions matched to your resume, with what great looks like, red flags to avoid, and which of your experiences to use for each one.
Your report selects 12 questions ranked by likelihood given your specific profile — and for each one, identifies the story from your resume you should tell and the angle most likely to land with Meta's interviewers.
How to Prepare for the Meta Data Engineer Interview
A structured prep framework based on how Meta actually evaluates Data Engineer candidates. Work through these focus areas in order — how much time you spend on each depends on your timeline and starting point.
Phase 1: Understand the Game
Before you prep anything, understand how Meta actually evaluates you
Learn how Meta's Meta Core Values work in practice — not as corporate values, but as the actual rubric interviewers use to score you
Understand that two evaluation tracks run simultaneously in every interview: technical depth and Meta Core Values. Most candidates over-index on one
Learn what the Product Analytics Org — Product Sense Required process means and how it changes the interview dynamic
Build the technical competency Meta expects for this role
Master Presto/Spark SQL with window functions, CTEs, and complex joins for funnel analysis and cohort retention queries
Practice pandas DataFrame operations, dictionary manipulation, and list processing for data transformation tasks
Study dimensional modeling fundamentals: star schema design, slowly changing dimensions, and bridge tables for many-to-many relationships
Learn social platform data patterns: user event tables, engagement metrics, and time-series aggregations at scale
Practice translating product goals into metric definitions and data architecture decisions
Practice explaining your approach while you solve, not after. Interviewers score your process, not just the answer
Phase 3: Meta Core Values Preparation
Not a separate "behavioral round" — woven into every interview
Meta Core Values questions are integrated into the behavioral round and woven into technical discussions, where interviewers probe how your data engineering decisions align with Meta's values of moving fast and building social value.
Build 2–3 strong experiences per Meta Core Values principle — not one per principle
Each experience needs a measurable outcome. Quantify impact wherever possible — business results, scale, adoption, or efficiency gains with real numbers
Your experiences must be real and traceable to your actual background. Interviewers probe deeply — vague or fabricated stories fall apart under follow-up questions
Focus first on the most frequently tested principles for this role: Move Fast — built or shipped a data pipeline or schema change quickly under ambiguity rather than waiting for perfect requirements, Be Bold — proposed a data architecture or metric definition that challenged the existing approach and delivered better outcomes, Focus on Long-Term Impact — designed a data model or pipeline with scalability and maintainability in mind, not just the immediate use case
Phase 4: Integration
The phase most candidates skip — and most regret
Simulate the product-to-pipeline exercise by taking a product goal like 'measure Instagram Reels discovery effectiveness' and working through metric definition, schema design, and ETL SQL implementation in one continuous 60-minute session.
Practice out loud, timed, from start to finish. Silent practice does not prepare you for the pressure of speaking under scrutiny
Identify your weakest Meta Core Values area and your weakest technical area. Spend disproportionate final-week time there — interviewers will probe your gaps
Do a full dry-run 2–3 days before your interview. Not the day before — you need time to course-correct
Meta-Specific Tip
Meta evaluates product sense as a first-class requirement alongside SQL and data modeling, requiring you to translate business goals into technical data solutions in real-time.
Watch Out For This
“We want to measure the success of a new Instagram Stories feature. Walk me through how you would design the data infrastructure to support this — from metrics to schema to pipeline.”
The flagship Meta DE full-stack question — tests the complete DE skill set in one exercise: product sense (what metrics matter?), data modeling (how do you structure the schema?), and SQL/ETL (how do you build the pipeline?). This mirrors the actual onsite full-stack round.
Your report includes the full answer framework for this question and Meta's other curveball questions — mapped to your specific background.
This plan works for any Meta Data Engineer candidate.
Your report makes it specific to you — the exact gaps in your background, the exact questions your resume makes likely, and a clear picture of exactly what to focus on given your specific risks.
Your report includes 8 stories pre-drafted from your resume, each mapped to a specific Meta Meta Core Values and competency. You practice answers — you don't write them from scratch the week before your interview.
You've worked too hard for your resume to fail the Meta DE interview. Walk in knowing your 3 biggest red flags — and exactly what to say when they surface.
Not hoping you prepared the right things. Knowing.
Your report starts with your resume, scores you against this exact role, and tells you which Meta Core Values you can prove with evidence — and which ones Meta will probe. Then it shows you exactly what to do about the gaps before they find them. Your STAR stories are pre-drafted from your own experience. Your gap scripts are written for your specific vulnerabilities. Nothing generic.
This Page — Free Guide
✓ What Meta looks for in any DE
✓ Most likely questions from reported interviews
✓ General prep framework
🔒 How your background measures up
🔒 Your 12 specific questions
🔒 Scripts for your gaps
→
Your Report — Personalized
✓ Your 3 biggest red flags — identified by name
✓ Exact bridge scripts for each gap
✓ Your STAR stories pre-drafted from your resume
✓ Question types most likely for your background
✓ Your experiences mapped to Meta Core Values
✓ Your fit score against this exact role
What's Inside Your 55-Page Report
1
Orientation
The unspoken bar Meta sets — what most candidates miss before they even walk in
2
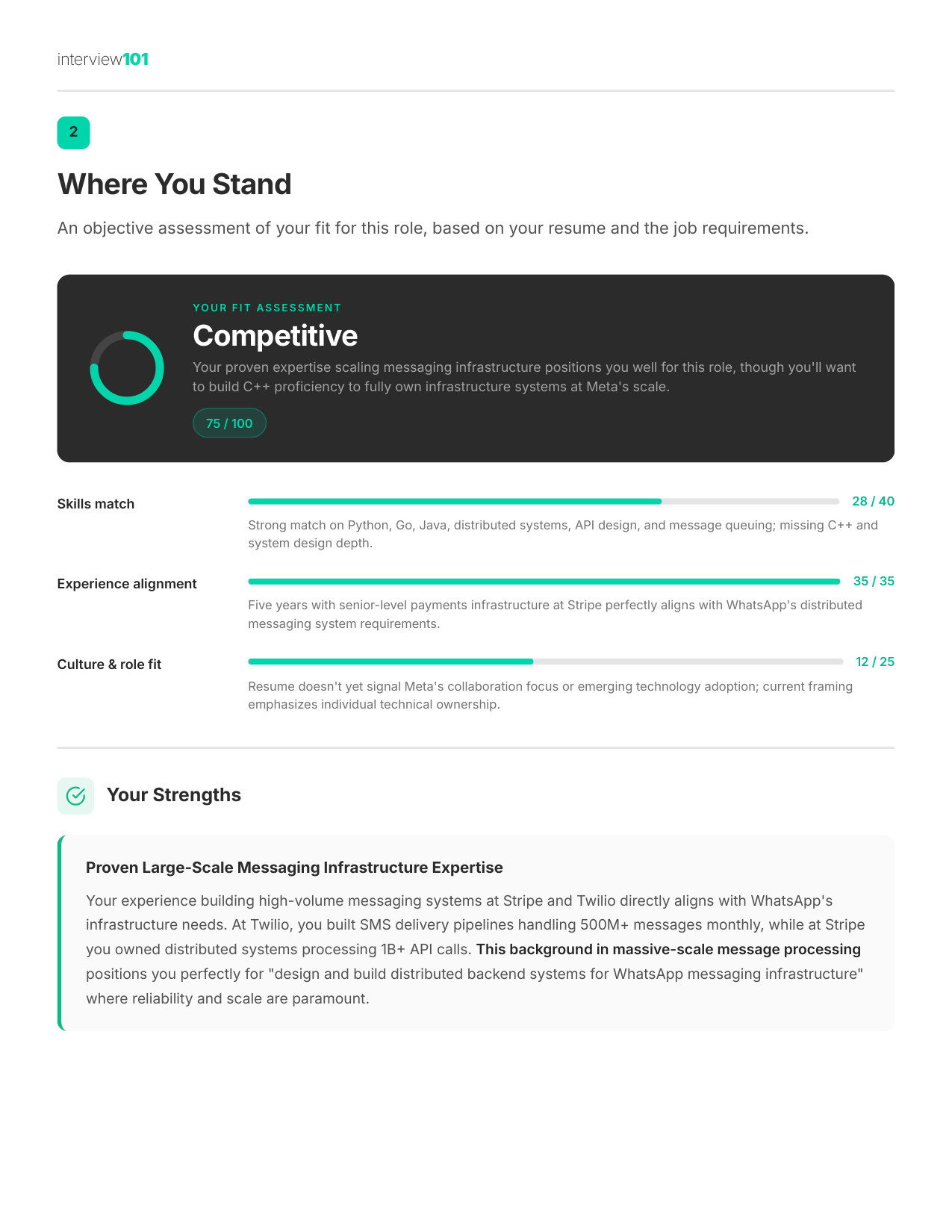
Where You Stand
Your fit score by skill, experience, and culture fit — know your strengths before they probe your gaps
3
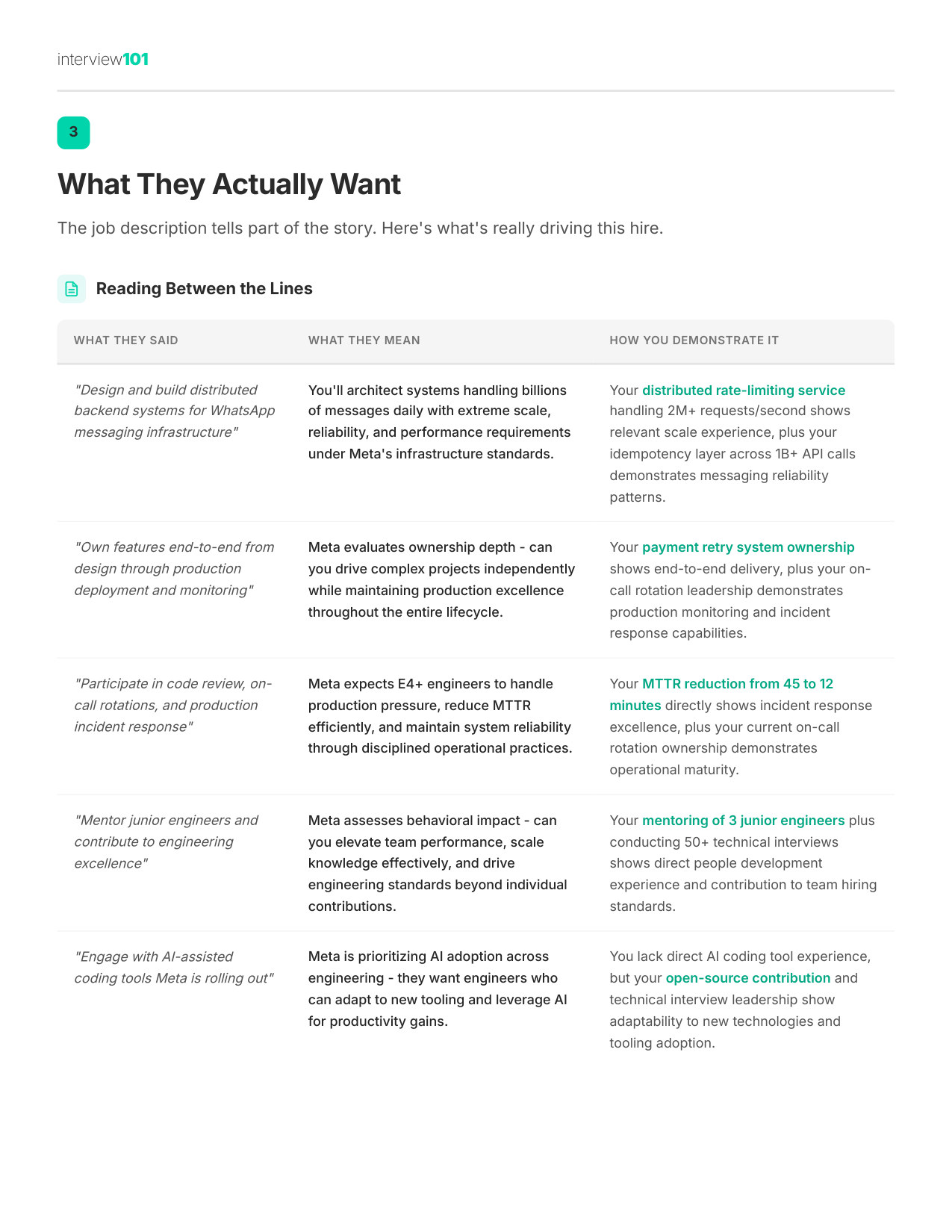
What They Actually Want
The real criteria interviewers score you on — beyond what the job description says
4
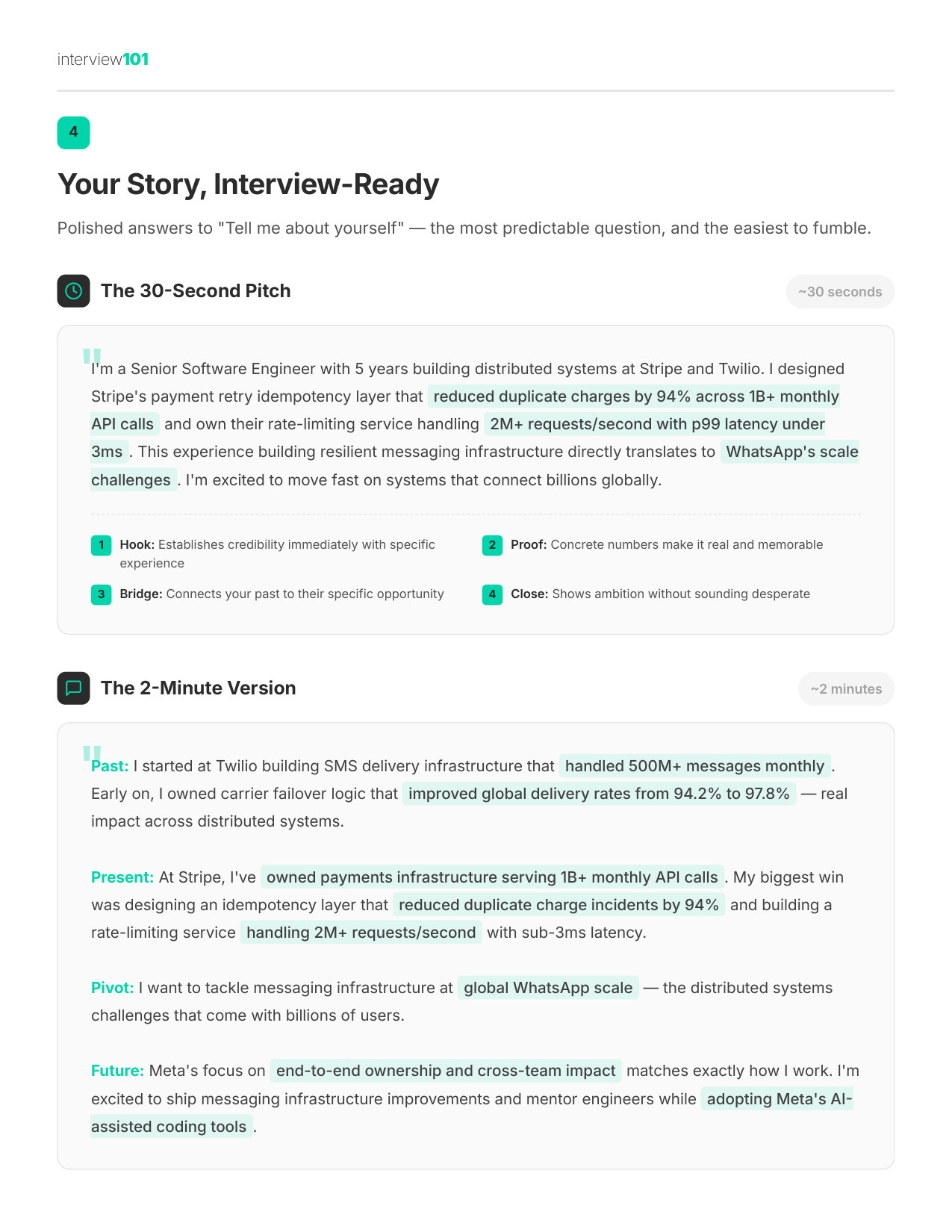
Your Story
Your resume reframed for Meta's lens — how to position your background so it lands
5
Experience That Wins
Your specific experiences mapped to the Meta Core Values you'll face — walk in knowing which examples to use
6
Questions You Will Face
The question types most likely given your background — with what a strong answer looks like for someone in your position
7
Scripts for Awkward Questions
Exact words for when they probe your weakest areas — so you do not freeze when it matters most
8
Questions to Ask Them
Sharp questions that signal preparation and seniority — and make interviewers remember you
9
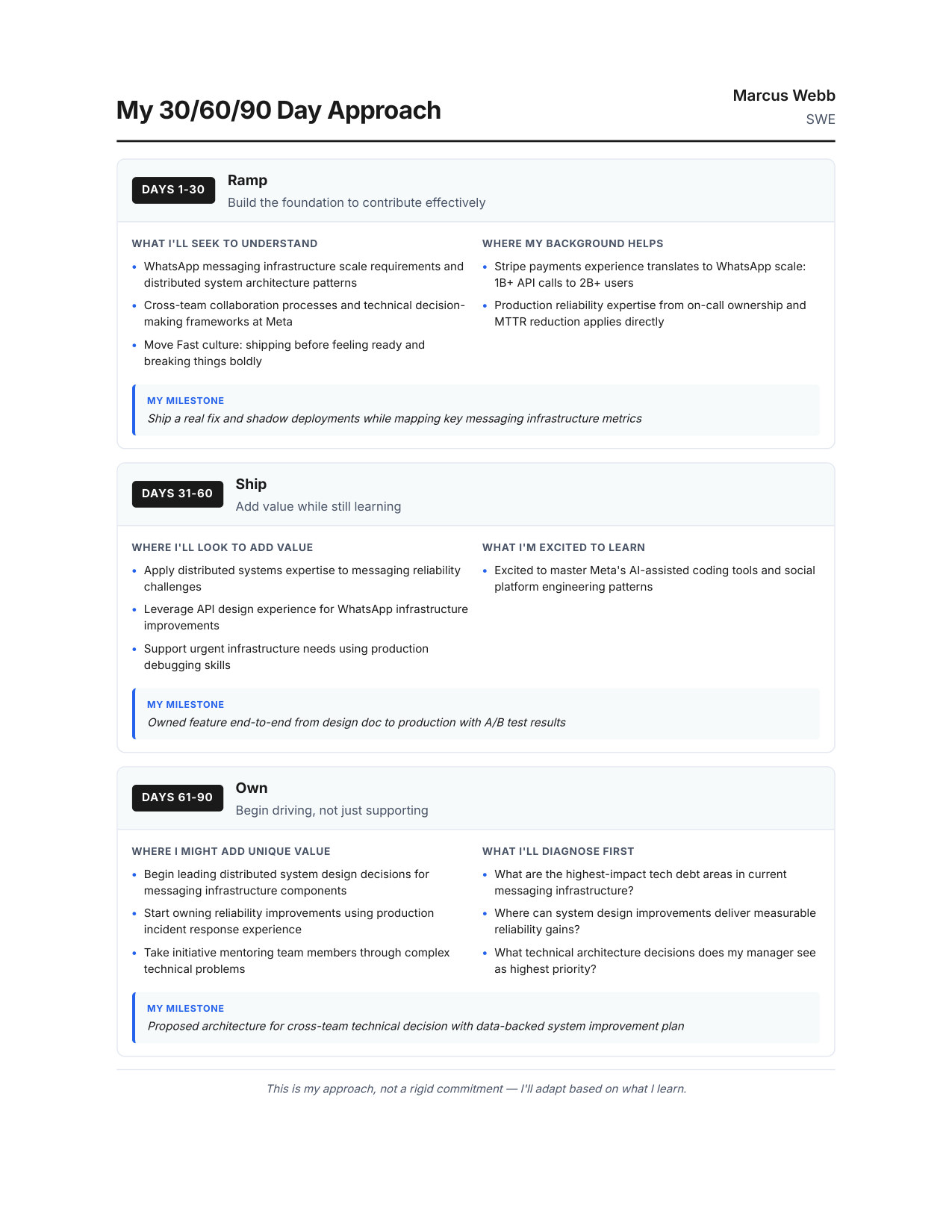
30/60/90 Day Plan
Show Meta you're already thinking like an employee — demonstrates ownership from day one
10
Interview Day Cheat Sheet
One page. Everything you need. Review 5 minutes before you walk in — and walk in ready.
How It Works
1
Upload your resume + target JD
The job description you're actually applying to — not a generic one
2
We analyze your fit
Your background is scored against the Meta DE blueprint — gaps, strengths, likely questions
3
Your report arrives within 24 hours
55-page personalized PDF delivered to your inbox — ready to work through before your interview
See Inside the Report
Real pages from a Meta Software Engineer report
Your DE report follows the same structure — built entirely around your background and this role.
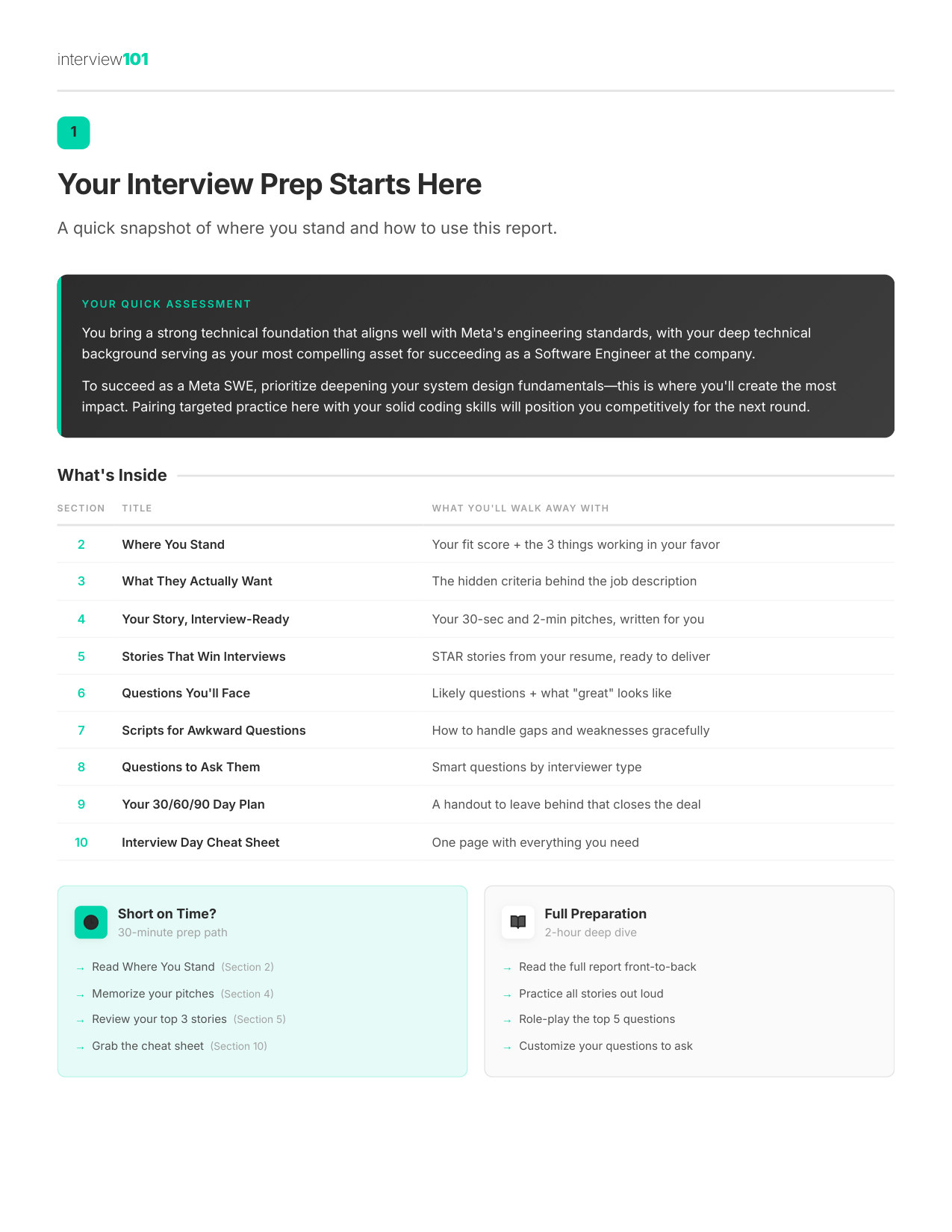
1 / 11Your Interview Prep Starts Here
Zoom
2 / 11Where You Stand
Zoom
3 / 11What They Actually Want
Zoom
4 / 11Your 2-Minute Pitch
Zoom
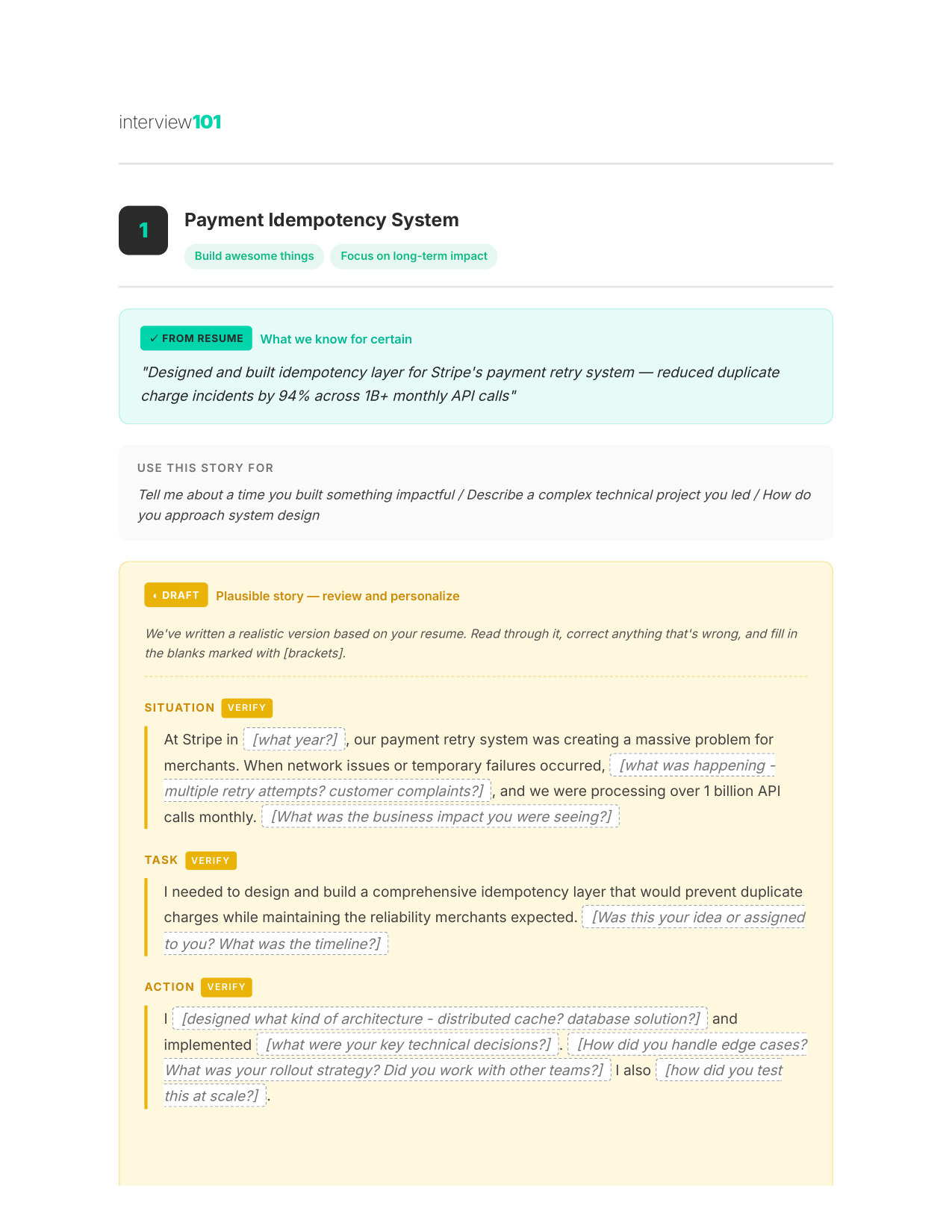
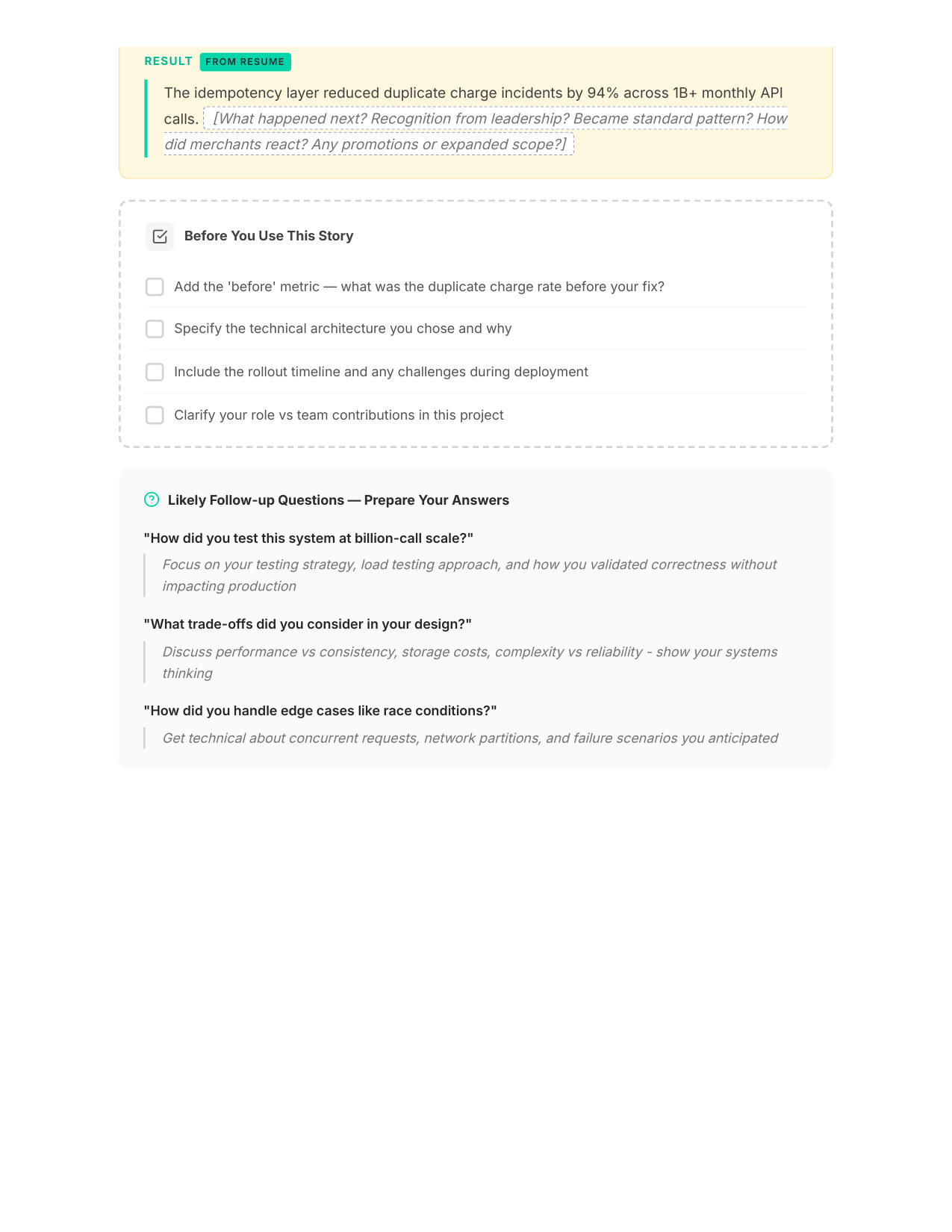
5 / 11Your STAR Story (Page 1)
Zoom
6 / 11Your STAR Story (Page 2)
Zoom
7 / 11Questions You'll Face
Zoom
8 / 11Scripts for Awkward Questions
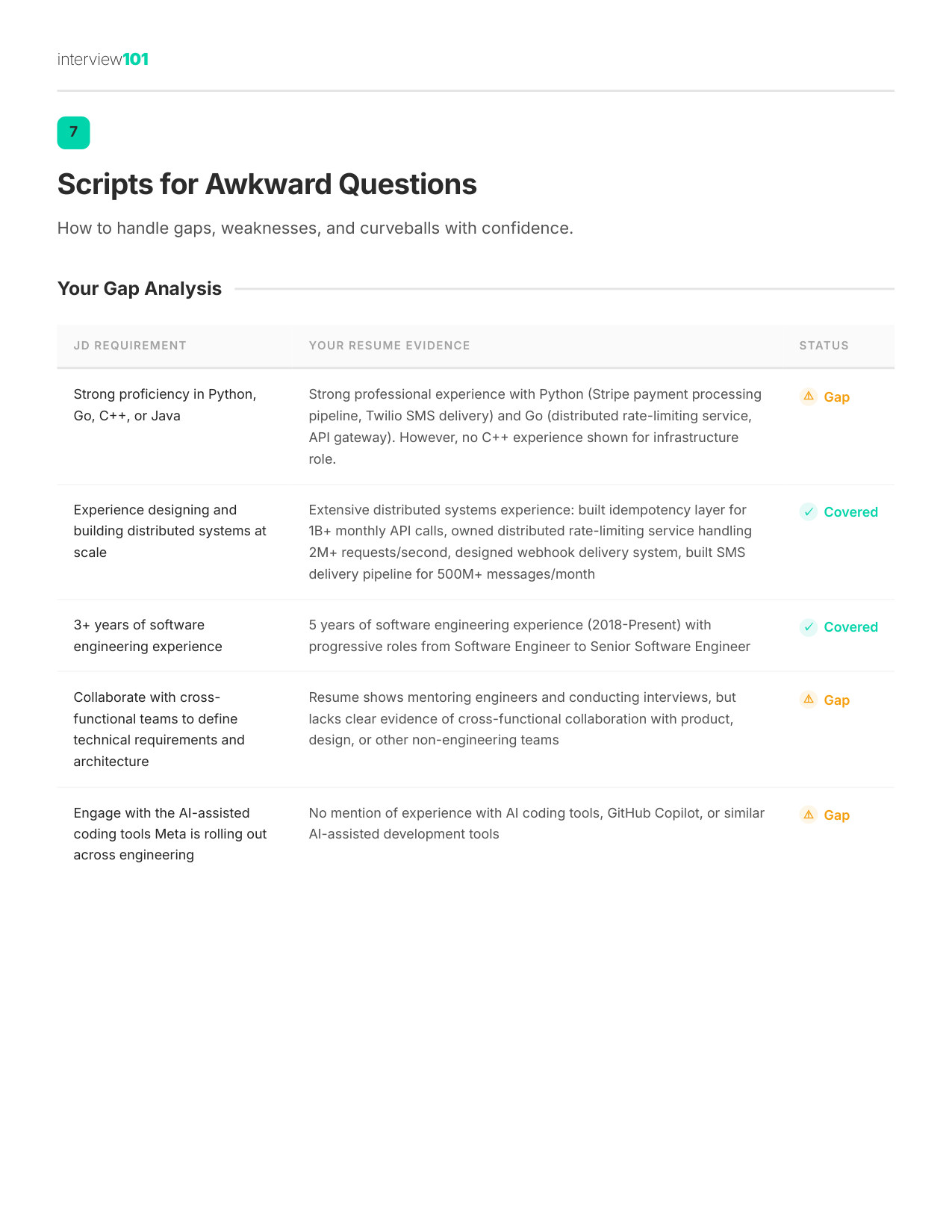
Zoom
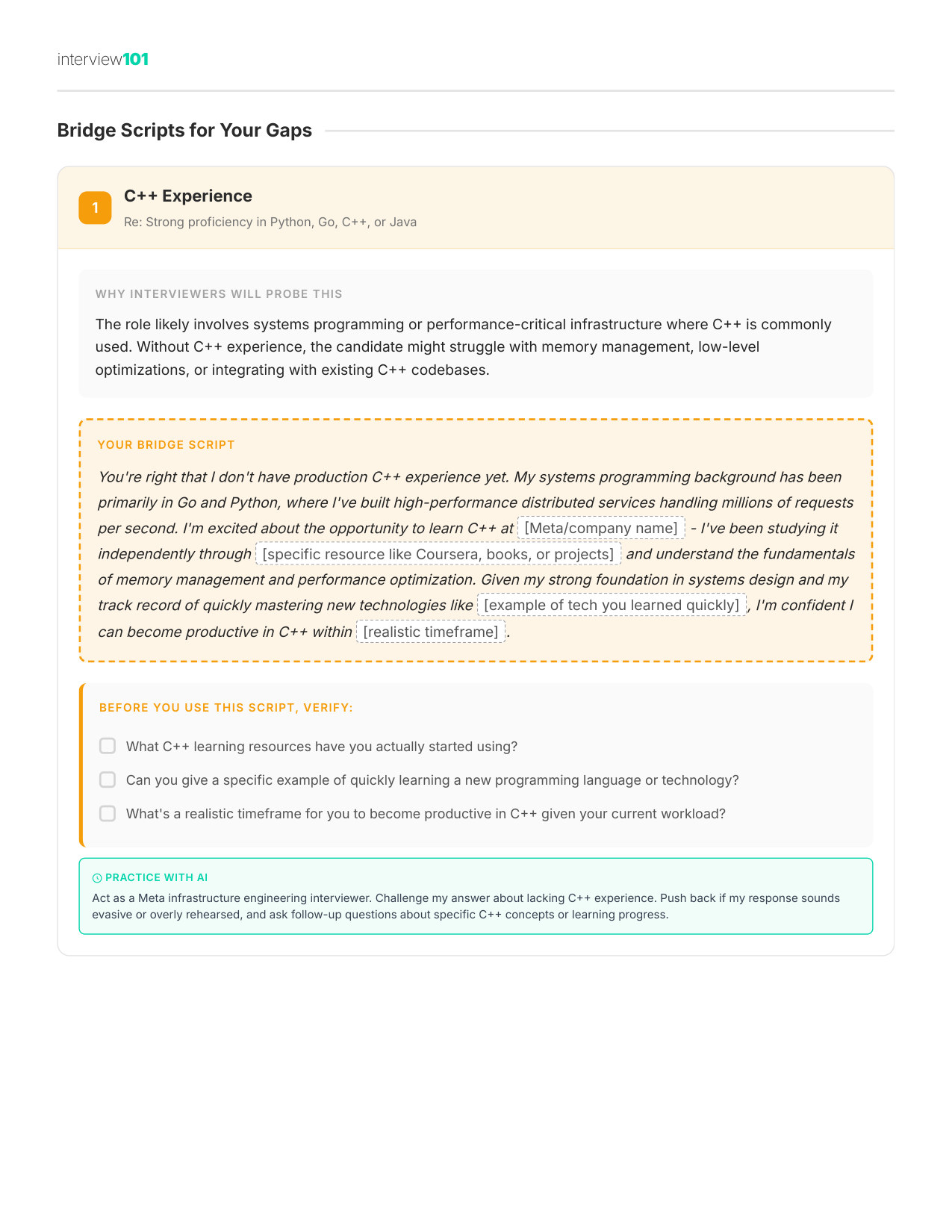
9 / 11Your Gap Script
Zoom
10 / 1130/60/90 Day Plan
Zoom
11 / 11Interview Day Cheat Sheet
Zoom
Download the Full Sample Report — Free
See exactly what you're buying before you commit — 50+ pages, no email required
🔒 30-day money-back guarantee — no questions asked
FAQ
Common Questions About the Meta Data Engineer Interview
The Meta Data Engineer interview process typically takes 3-5 weeks from application to offer. This includes time for the initial technical screen, scheduling the onsite loop, and final decision-making. The timeline can vary based on scheduling availability and how quickly you move through each stage.
Meta's Data Engineer interview process consists of 5 rounds total: a Technical Screen (60 min), followed by 4 onsite rounds covering Advanced SQL/Coding (45-60 min), Data Modeling (45-60 min), Product Sense/Full-Stack (60 min), and Behavioral/Ownership (45 min). Each round evaluates different technical and cultural competencies required for the role.
The most critical preparation is the unique technical screen format: 5 SQL questions + 5 Python questions in 1 hour on CoderPad, where you must pass at least 3 of 5 in each category to advance. Speed and efficiency are the primary signals, so practice solving medium-hard SQL problems with window functions and Python data manipulation tasks quickly and accurately.
You must wait 6 months after a rejection before reapplying to Meta for any role, including Data Engineer positions. This cooldown period gives you time to strengthen your skills and ensures you're presenting your best self when you reapply.
Yes, Meta Core Values questions appear in every interview round alongside technical questions, not just in a dedicated behavioral round. The framework assesses how you demonstrate Meta's cultural principles through your past experiences, decision-making, and approach to challenges throughout the entire interview process.
For SQL, expect medium-hard problems using Presto/Spark SQL with window functions, CTEs, self-joins, funnel analysis, and time-series aggregations on large-scale event tables. For Python, focus on data manipulation with pandas DataFrames, dictionary operations, list processing, and string manipulation - NOT algorithm practice or data structure problems.
This page shows you what the Meta Data Engineer interview looks like in general. Your personalized report shows you how to prepare specifically — using your resume, a real job description, and Meta's actual evaluation criteria.
This page shows every Meta DE candidate the same thing. Your report is built around you — your resume, your gaps, your most likely questions.
What's inside: your fit score broken down by skill, experience, and culture; your top 3 risk areas by name; the 12 questions most likely for your specific background with full answer decodes; your experiences mapped to the Meta Core Values you'll face; scripts for when they probe your weakest spots; sharp questions to ask your interviewers; and a one-page cheat sheet to review before you walk in. 55 pages. Delivered within 24 hours.
Within 24 hours. Your report is reviewed and delivered to your inbox within 24 hours of payment. Most orders arrive significantly faster. You'll receive an email with your personalized PDF as soon as it's ready.
30-day money-back guarantee, no questions asked. If your report doesn't help you feel more prepared, email us and we'll refund in full.