GPU-Hardware-Aware ML — Inference Optimization + Distributed Training at Scale
4–8
Weeks Timeline
Application to offer
$266–490K
Total Compensation
Base + Stock + Bonus
Questions sourced from reported interviews
Every claim traced to a verified source
Updated quarterly — data stays current
2,600+ reported interviews analyzed
Self-Assessment
Is This Role Right for You?
See what NVIDIA looks for in Machine Learning Engineer candidates and check how you measure up.
What strong candidates bring to the role:
Strong candidates bring hands-on experience profiling and optimizing ML workloads on GPU hardware, including familiarity with CUDA programming concepts, memory coalescing patterns, and performance analysis tools like Nsight Compute or Nsight Systems.
Strong candidates bring experience designing or operating distributed training systems across multiple GPUs, with specific knowledge of parallelism strategies, gradient synchronization, and communication optimization at scale.
Strong candidates bring production experience with model compression techniques, inference serving optimization, and performance validation methodologies for deployed ML systems.
Strong candidates bring experience collaborating across hardware and software teams, making ML architectural decisions informed by hardware constraints, and validating performance claims through rigorous measurement.
What NVIDIA Looks For
NVIDIA rewards candidates who reason transparently at the hardware-software boundary — engineers who can explain why FlashAttention reduces memory bandwidth requirements or how NCCL topology affects 64-GPU training convergence consistently outperform those who only understand ML algorithms without their hardware implications.
Free — Takes 60 seconds
See your personal gap risk profile
Upload your resume and your target job description. Get your fit score, your top 3 risks, and exactly what to prepare first — before you spend another hour prepping the wrong things.
Machine Learning Engineers at NVIDIA build the ML infrastructure that powers the world's AI applications — from LLM inference serving on H100 clusters to real-time robotics policies on Jetson devices. Unlike MLEs at other companies who treat GPU optimization as a DevOps afterthought, NVIDIA MLEs architect ML systems with deep hardware awareness, making decisions about model parallelism, quantization strategies, and kernel fusion based on tensor core utilization and HBM bandwidth constraints.
What's Different at NVIDIA
NVIDIA rewards candidates who reason transparently at the hardware-software boundary — engineers who can explain why FlashAttention reduces memory bandwidth requirements or how NCCL topology affects 64-GPU training convergence consistently outperform those who only understand ML algorithms without their hardware implications.
GPU Hardware Awareness
Every technical round evaluates whether you understand how ML architectural decisions translate to GPU execution efficiency. You must demonstrate knowledge of memory hierarchies, tensor core utilization patterns, and the hardware-level motivations behind techniques like quantization and KV-cache paging. Interviewers probe for specific performance metrics and bottleneck analysis from your past projects.
Inference Optimization Depth
NVIDIA treats inference optimization as a first-class MLE competency, not a deployment detail. You'll face direct questions about TensorRT graph optimization, Triton serving architecture, and quantization algorithm implementation. Panel interviews often include deep-dives into how you've optimized model serving latency and throughput in production systems.
Distributed Training Systems
System design questions assume expertise with training at 64+ GPU scale, covering FSDP versus tensor parallelism tradeoffs, NCCL communication patterns, and gradient checkpointing strategies. You must articulate specific architectural decisions based on model size, hardware topology, and convergence requirements rather than generic distributed training concepts.
Your Report Adds
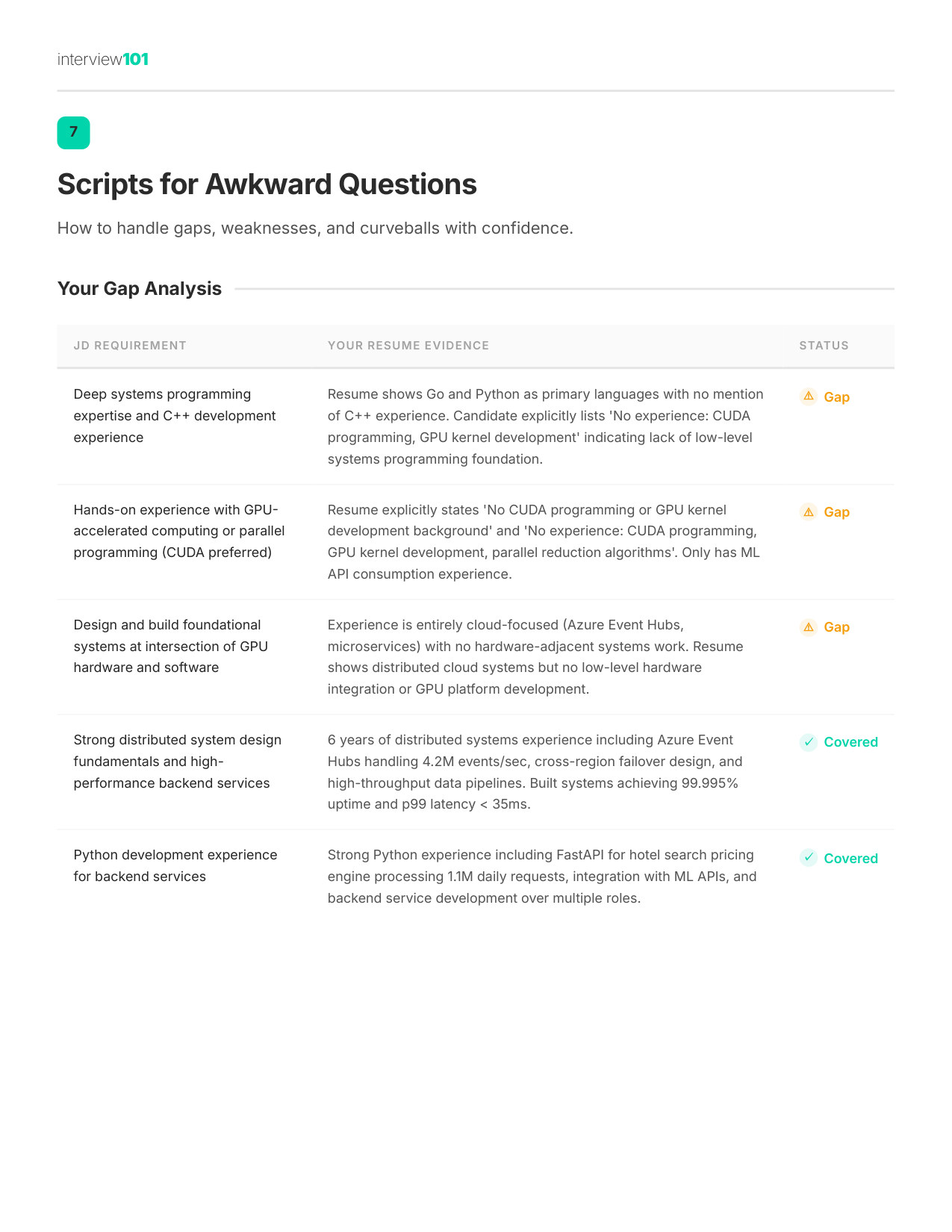
NVIDIA's NVIDIA Values are mapped directly to the bullet points on your resume. You'll see exactly which ones you can claim with evidence — and which ones are gaps to address before the interview.
The NVIDIA Machine Learning Engineer Interview Process
The NVIDIA Machine Learning Engineer interview timeline varies by team — confirm the specifics with your recruiter.
Important: NVIDIA MLE interview loops are highly team-specific — the technical depth, domain focus, and round structure vary significantly between inference optimization roles (TensorRT-LLM, NIM), training infrastructure roles (DGX, FSDP at scale), robotics ML roles (Isaac Lab, physical AI), graphics AI roles (DLSS, NeRF, diffusion for rendering), and scientific computing ML roles. The consistent elements: GPU hardware awareness is evaluated in every round, project portfolio deep-dives are a primary tool, and intellectual honesty about hardware-ML knowledge boundaries is scored. Panel-style rounds (multiple engineers) are common. 4-6 rounds total. Always verify the specific team's technical focus with your recruiter. Process is slow — 6-10 weeks total, 2+ weeks post-onsite is normal.
1
Online Assessment
60-90 min
Some roles include a coding assessment covering medium-to-hard algorithm problems and ML implementation tasks before the onsite rounds.
Evaluates
Coding fundamentals and ML algorithm implementation
2
ML Depth Rounds
45-60 min each
Three rounds focusing on GPU-aware ML engineering: implementing attention mechanisms, quantization algorithms, or CUDA kernel analysis combined with theoretical depth questions.
Evaluates
Hardware-aware ML implementation and system optimization knowledge
3
Project Portfolio Deep-dive
60 min
Panel-style interview where multiple engineers probe your past ML projects for GPU utilization metrics, performance bottlenecks, and hardware-aware optimization decisions.
Evaluates
Real-world GPU ML systems experience and quantitative performance measurement
4
System Design
45-60 min
Design GPU-infrastructure-aware ML systems like LLM serving clusters, distributed training pipelines, or real-time inference systems with specific hardware constraints.
Evaluates
Large-scale ML system architecture with GPU hardware considerations
5
Values Assessment
45 min
Behavioral interview anchored in NVIDIA Values, with emphasis on innovation in ML systems and intellectual honesty about hardware-software boundaries.
Evaluates
Cultural alignment and leadership principles through ML engineering lens
Round Breakdown — Machine Learning Engineer
Behavioral Culture
17%
Ml Depth Gpu Aware
25%
Coding Ml Implementation
17%
Project Portfolio Deepdive
17%
System Design Inference Or Training
25%
Your Report Adds
Your report includes a stage-by-stage prep checklist built around your background — what to emphasize in each round, based on the specific gaps between your resume and this role.
At NVIDIA, every Machine Learning Engineer candidate is evaluated against their NVIDIA Values. Expand each one below to see what interviewers are actually looking for.
Technical EvaluationAssessed alongside NVIDIA Values in every round
GPU Programming Experience
Strong candidates bring hands-on experience profiling and optimizing ML workloads on GPU hardware, including familiarity with CUDA programming concepts, memory coalescing patterns, and performance analysis tools like Nsight Compute or Nsight Systems.
Large-Scale Training Infrastructure
Strong candidates bring experience designing or operating distributed training systems across multiple GPUs, with specific knowledge of parallelism strategies, gradient synchronization, and communication optimization at scale.
Model Optimization and Deployment
Strong candidates bring production experience with model compression techniques, inference serving optimization, and performance validation methodologies for deployed ML systems.
Hardware-Software Co-design
Strong candidates bring experience collaborating across hardware and software teams, making ML architectural decisions informed by hardware constraints, and validating performance claims through rigorous measurement.
All NVIDIA Values — click any to see how to demonstrate it
NVIDIA defines innovation as creating new ML system architectures that fundamentally change how models execute on GPUs, not just tuning hyperparameters or applying existing frameworks. This means designing novel distributed training strategies, creating custom memory management for large models, or building new abstractions that unlock GPU capabilities that standard frameworks can't access. NVIDIA interviewers evaluate whether you've solved problems that required inventing new approaches rather than implementing well-known solutions.
How to Demonstrate: Come prepared with examples where you built custom CUDA kernels, designed novel tensor parallelism strategies, or created new memory optimization techniques that weren't available in existing libraries. Focus on the systems-level innovation — explain why existing solutions couldn't work and how your approach fundamentally changed the performance characteristics or capabilities of the ML pipeline. Interviewers want to see that you identified a gap in current ML infrastructure and filled it with something genuinely new, not just a clever application of existing tools. The strongest answers show how your innovation enabled new classes of models or workloads that weren't previously feasible.
NVIDIA values candidates who clearly distinguish between what they know definitively versus what they're reasoning through when discussing GPU hardware details. This means being explicit about the limits of your knowledge while still demonstrating solid reasoning about hardware-software interactions. NVIDIA interviewers test this by asking progressively detailed questions about GPU architecture, memory systems, or CUDA execution models to see where candidates draw honest boundaries around their expertise.
How to Demonstrate: When asked about specific GPU details, clearly state your level of certainty and show your reasoning process. Instead of guessing at specific numbers, explain the principles you'd use to find the answer and what you'd expect to see. For example, 'I haven't measured this exact scenario, but based on the memory access pattern being strided, I'd expect memory bandwidth to be the bottleneck and would profile with Nsight to confirm.' Interviewers reward candidates who demonstrate strong first-principles reasoning while acknowledging knowledge gaps, rather than those who either guess incorrectly or claim no knowledge at all.
NVIDIA operates on hardware release cycles that demand rapid ML system development, often requiring architectural decisions before complete information is available about new GPU capabilities or model requirements. This means building systems that can adapt quickly to new hardware features, making smart trade-offs when time is limited, and validating approaches through production deployment rather than exhaustive offline analysis. NVIDIA interviewers assess whether candidates can balance speed with quality in high-pressure ML system development.
How to Demonstrate: Share specific examples of ML system decisions you made under tight deadlines, focusing on how you prioritized what to build versus what to defer. Explain situations where you had to choose between multiple architectural approaches with limited data, how you made the decision, and how you validated it quickly in production. Emphasize your ability to identify the minimum viable technical solution that could be shipped and iterated on, rather than waiting for the perfect design. Strong answers show you can rapidly prototype ML system changes, measure their impact with production metrics, and iterate based on real performance data rather than theoretical analysis.
NVIDIA's ML systems require deep collaboration between teams that typically work in isolation at other companies — ML engineers must work directly with CUDA kernel developers, hardware architects, and compiler teams to optimize end-to-end performance. This means ML architectural decisions are made with direct input from hardware constraints, and hardware features are designed with specific ML workload patterns in mind. NVIDIA interviewers evaluate whether candidates can bridge these domains and work effectively across traditional boundaries.
How to Demonstrate: Provide concrete examples of working with low-level systems teams to optimize ML performance, focusing on how you translated ML requirements into hardware or kernel constraints and vice versa. Describe situations where you modified model architectures based on direct feedback from CUDA engineers, or where you worked with hardware teams to influence accelerator design for your ML workloads. The strongest answers show bidirectional influence — not just consuming hardware capabilities, but actively shaping them based on ML system needs. Demonstrate that you can communicate ML performance requirements in terms that hardware and systems engineers can act on, and that you incorporate their constraints into your ML design decisions.
NVIDIA requires ML engineers to make performance claims backed by rigorous measurement using professional profiling tools, not intuition or high-level framework metrics. This means using tools like Nsight Compute to identify actual kernel bottlenecks, Nsight Systems to understand end-to-end pipeline performance, and establishing proper benchmarking methodologies that isolate optimization impacts. NVIDIA interviewers assess whether candidates can distinguish between perceived performance improvements and measured ones, and whether they understand how to validate optimizations scientifically.
How to Demonstrate: Come with specific examples of using Nsight tools or similar profilers to identify performance bottlenecks that weren't obvious from high-level metrics. Describe situations where your initial hypothesis about a bottleneck was wrong and profiling revealed the actual issue. Show how you established rigorous before/after benchmarking that controlled for variability and isolated the impact of specific optimizations. Strong answers demonstrate that you can move beyond 'training got faster' to specific metrics like 'reduced memory bandwidth utilization from 85% to 60% by changing the attention kernel's memory access pattern, validated across 10 runs with consistent 1.3x speedup.' Interviewers want to see that you treat performance optimization as a scientific process, not guesswork.
Your Report Adds
Your report scores you against each of these criteria using your resume and the job description — you get a ranked list of where you're strong vs. where you need to build a case before your interview.
Showing 12 questions drawn from 2,600+ reported interviews — ranked by frequency for NVIDIA Machine Learning Engineer candidates.
Your report selects the 12 questions you're most likely to face based on your resume.
Get yours →
Behavioral2 questions
"Tell me about a time when you had to optimize an ML system's performance but found that the bottleneck wasn't where you initially expected. How did you diagnose the real issue, and what did you learn about the hardware-software interaction?"
BehavioralIntellectual honesty about hardware-ML intersection
· Reported 31 times
What they're really asking
NVIDIA is testing whether you actually profile and measure rather than make assumptions about performance bottlenecks. They want to see if you use proper GPU profiling tools and can admit when your initial hypothesis was wrong. This reveals whether you approach optimization with engineering rigor or just intuition.
What Great Looks Like
Demonstrates using specific profiling tools like Nsight Compute or Systems, shows willingness to be wrong about initial assumptions, and connects the discovery to a deeper understanding of GPU memory hierarchy or compute patterns. Includes quantitative before/after metrics.
What Bad Looks Like
Makes vague claims about 'optimizing the model' without profiling tools, never admits being wrong about the bottleneck, or focuses purely on algorithmic changes without any hardware performance context.
"Describe a situation where you had to ship an ML feature under tight deadline pressure, but the initial approach wasn't working. How did you adapt your technical strategy while maintaining quality?"
BehavioralSpeed and agility in ML iteration
· Reported 28 times
What they're really asking
NVIDIA operates on hardware release cycles with fixed deadlines, so they need MLEs who can pivot quickly without compromising engineering standards. This tests whether you can make pragmatic technical decisions under pressure while still delivering production-quality results.
What Great Looks Like
Shows a clear pivot in technical approach with specific reasoning, maintains testing and validation standards even under pressure, and demonstrates how you communicated the change to stakeholders. Includes concrete timeline and quality metrics.
What Bad Looks Like
Suggests cutting corners on testing or validation, shows indecision rather than clear pivoting, or focuses on working longer hours rather than changing the technical approach.
Ml Depth3 questions
"Walk me through the memory access patterns in standard multi-head attention versus FlashAttention. Why does the standard implementation become memory-bound at long sequences, and how does FlashAttention's tiling strategy address this?"
Ml Depth
· Reported 42 times
What they're really asking
This tests deep understanding of how attention mechanisms interact with GPU memory hierarchy. NVIDIA wants MLEs who understand that ML performance isn't just about FLOPs but about memory bandwidth, cache locality, and how algorithmic choices map to hardware execution patterns.
"Explain how gradient accumulation works in distributed training and why it becomes memory-critical with large language models. What are the tradeoffs between accumulating gradients in FP16 vs FP32?"
Ml Depth
· Reported 39 times
What they're really asking
NVIDIA is evaluating whether you understand the memory implications of distributed training at scale, especially for models that approach or exceed single-GPU memory limits. This tests knowledge of how precision choices affect both memory usage and numerical stability in gradient updates.
"You're deploying a vision transformer for real-time inference on Jetson AGX. The model has 22M parameters and needs to run at 30 FPS with 50ms latency budget. Walk through your optimization strategy from model architecture to hardware utilization."
Ml Depth
· Reported 35 times
What they're really asking
This tests whether you can reason about the entire optimization stack from model design to edge hardware constraints. NVIDIA wants to see if you understand how model architecture decisions (patch size, attention heads, etc.) translate to actual Jetson performance given its specific compute and memory capabilities.
"Implement a quantized linear layer forward pass in Python. Your implementation should handle INT8 weights and activations with per-channel quantization scales. Include the dequantization, matrix multiplication, and requantization steps."
Coding
· Reported 44 times
What they're really asking
NVIDIA is testing whether you understand quantization at the implementation level, not just conceptually. They want to see if you can write the actual arithmetic for INT8 inference, including how scales and zero-points work in practice. This reveals depth of understanding about model deployment optimization.
"Write a Python function that implements ring AllReduce for gradient synchronization across N GPUs. Your function should handle the reduce-scatter and all-gather phases with proper indexing for arbitrary tensor sizes."
Coding
· Reported 38 times
What they're really asking
This tests understanding of how distributed training actually works under the hood, specifically the communication patterns that NCCL implements. NVIDIA wants MLEs who understand collective communication algorithms since they're fundamental to multi-GPU training performance.
"Pick your most GPU-performance-critical ML project. Walk me through a specific optimization you made that required understanding both the model architecture and the underlying CUDA execution. What was the performance impact and how did you measure it?"
Project Portfolio Deepdive
· Reported 47 times
What they're really asking
NVIDIA is probing for evidence that you've worked at the intersection of ML and GPU hardware, not just applied high-level frameworks. They want to see that you can connect algorithmic choices to actual GPU execution patterns and that you measure performance rigorously.
"Tell me about a time when you had to debug an ML system performance issue that involved multiple components - model, infrastructure, and hardware. How did you isolate the problem and what tools did you use?"
Project Portfolio Deepdive
· Reported 41 times
What they're really asking
NVIDIA wants to understand your systematic debugging approach for complex ML systems. They're looking for evidence that you can work across the full stack from model code down to hardware utilization, using proper profiling tools rather than guessing.
"Design a real-time inference system for a multi-modal robotics policy that processes camera, lidar, and proprioception data on Jetson AGX. The policy needs 10ms latency end-to-end with 20Hz sensor updates. How do you handle sensor fusion, model optimization, and maintain deterministic timing?"
System Design
· Reported 33 times
What they're really asking
This tests whether you can design ML systems for real-time robotics constraints, which require understanding both Jetson hardware capabilities and real-time system design. NVIDIA wants to see if you can balance model complexity, sensor processing, and deterministic execution timing.
"Design a TensorRT optimization pipeline for deploying a large vision transformer model. Walk through ONNX export, graph optimizations, INT8 calibration dataset selection, and performance validation on A100 vs H100."
System Design
· Reported 36 times
What they're really asking
NVIDIA is testing depth of knowledge about their TensorRT inference optimization stack. They want to see if you understand the full pipeline from model export through hardware-specific optimization, including how different GPU architectures affect optimization strategies.
"Design a continuous batching inference server for a 13B parameter LLM running on 4x H100 GPUs. Handle variable sequence lengths, KV-cache management across requests, and implement speculative decoding. What's your memory allocation strategy and how do you handle request scheduling?"
System Design
· Reported 40 times
What they're really asking
This tests understanding of modern LLM serving challenges including memory management for attention caches and request batching optimization. NVIDIA wants to see if you understand how KV-cache memory grows with sequence length and how to efficiently pack variable-length sequences for GPU utilization.
These are the questions NVIDIA Machine Learning Engineer candidates report facing most. Your report takes it further — 12 questions matched to your resume, with what great looks like, red flags to avoid, and which of your experiences to use for each one.
Your report selects 12 questions ranked by likelihood given your specific profile — and for each one, identifies the story from your resume you should tell and the angle most likely to land with NVIDIA's interviewers.
How to Prepare for the NVIDIA Machine Learning Engineer Interview
A structured prep framework based on how NVIDIA actually evaluates Machine Learning Engineer candidates. Work through these focus areas in order — how much time you spend on each depends on your timeline and starting point.
Phase 1: Understand the Game
Before you prep anything, understand how NVIDIA actually evaluates you
Learn how NVIDIA's NVIDIA Values work in practice — not as corporate values, but as the actual rubric interviewers use to score you
Understand that two evaluation tracks run simultaneously in every interview: technical depth and NVIDIA Values. Most candidates over-index on one
Learn what the GPU-Hardware-Aware ML — Inference Optimization + Distributed Training at Scale process means and how it changes the interview dynamic
Study NVIDIA's official NVIDIA Values — understand the intent behind each principle, not just the name
Phase 2: Technical Foundation
Build the technical competency NVIDIA expects for this role
Implement attention mechanisms from scratch, progressing from basic scaled dot-product attention to FlashAttention-style memory-efficient variants with pseudocode for fused kernel operations
Practice quantization algorithm implementation including INT8 linear layer forward passes with scale and zero-point calculations, and calibration dataset selection strategies
Study distributed training primitives: ring AllReduce implementation, gradient accumulation with FSDP, and tensor/pipeline parallelism tradeoffs for large models
Review GPU memory hierarchy and performance characteristics: HBM bandwidth, tensor core utilization patterns, memory coalescing, and the hardware motivations behind common ML optimizations
Prepare project portfolio with specific GPU performance metrics: utilization percentages, memory bandwidth measurements, latency improvements, and optimization impact validation
Practice explaining your approach while you solve, not after. Interviewers score your process, not just the answer
Phase 3: NVIDIA Values Preparation
Not a separate "behavioral round" — woven into every interview
NVIDIA Values questions are woven throughout technical discussions, with interviewers probing for innovation in ML systems and intellectual honesty when technical questions reach the boundary of your hardware knowledge.
Build 2–3 strong experiences per NVIDIA Values principle — not one per principle
Each experience needs a measurable outcome. Quantify impact wherever possible — business results, scale, adoption, or efficiency gains with real numbers
Your experiences must be real and traceable to your actual background. Interviewers probe deeply — vague or fabricated stories fall apart under follow-up questions
Focus first on the most frequently tested principles for this role: Innovation in ML systems — show you have pushed the boundary of what ML infrastructure could do in your domain, not just applied standard techniques; NVIDIA interviewers are building the infrastructure the world's AI runs on and they hire MLEs who innovate at the systems level, not just the algorithm level, Intellectual honesty about hardware-ML intersection — demonstrate you reason transparently when questions reach the boundary of your GPU hardware knowledge; 'I understand the memory hierarchy conceptually but I haven't profiled this specific kernel — let me reason through what I would expect based on the attention pattern's memory access pattern' scores higher than a confident incorrect claim about HBM bandwidth numbers, Speed and agility in ML iteration — NVIDIA ships GPU architectures on aggressive timelines and the ML systems built on top of them must iterate equally fast; show you have shipped ML system improvements under real time pressure, made architectural decisions with incomplete information, and validated them in production
Phase 4: Integration
The phase most candidates skip — and most regret
Practice integrated sessions combining GPU-aware ML implementation coding with immediate follow-up questions about hardware performance implications and optimization strategies under time pressure.
Practice out loud, timed, from start to finish. Silent practice does not prepare you for the pressure of speaking under scrutiny
Identify your weakest NVIDIA Values area and your weakest technical area. Spend disproportionate final-week time there — interviewers will probe your gaps
Do a full dry-run 2–3 days before your interview. Not the day before — you need time to course-correct
NVIDIA-Specific Tip
NVIDIA rewards candidates who reason transparently at the hardware-software boundary — engineers who can explain why FlashAttention reduces memory bandwidth requirements or how NCCL topology affects 64-GPU training convergence consistently outperform those who only understand ML algorithms without their hardware implications.
Watch Out For This
“Explain why standard self-attention is memory-bandwidth-bound at long sequence lengths, and describe how FlashAttention addresses this. Then implement the core idea in pseudocode.”
This is NVIDIA's canonical MLE inference depth question — it appears in multiple NVIDIA MLE interview accounts (including the 2026 account where a candidate was asked to 'write an API call for a FlashAttention variant on the spot') and tests the deepest intersection of ML and GPU hardware knowledge that NVIDIA evaluates. FlashAttention is not just an algorithmic innovation — it is a memory access pattern optimization that works because of specific GPU memory hierarchy characteristics (HBM bandwidth vs SRAM bandwidth), and NVIDIA MLEs are expected to understand this at the hardware level, not just use it as a library call. The question tests three things simultaneously: understanding of why standard attention is memory-bandwidth-bound at long sequence lengths (materializing the N×N attention matrix in HBM), understanding of how FlashAttention fuses operations to keep intermediate results in SRAM, and the ability to implement the key idea in pseudocode or Python on the spot. Candidates who can only describe FlashAttention at the algorithmic level without connecting to GPU memory hierarchy fail the hardware-aware depth test.
Your report includes the full answer framework for this question and NVIDIA's other curveball questions — mapped to your specific background.
This plan works for any NVIDIA Machine Learning Engineer candidate.
Your report makes it specific to you — the exact gaps in your background, the exact questions your resume makes likely, and a clear picture of exactly what to focus on given your specific risks.
Your report includes 8 stories pre-drafted from your resume, each mapped to a specific NVIDIA NVIDIA Values and competency. You practice answers — you don't write them from scratch the week before your interview.
You've worked too hard for your resume to fail the NVIDIA MLE interview. Walk in knowing your 3 biggest red flags — and exactly what to say when they surface.
Not hoping you prepared the right things. Knowing.
Your report starts with your resume, scores you against this exact role, and tells you which NVIDIA Values you can prove with evidence — and which ones NVIDIA will probe. Then it shows you exactly what to do about the gaps before they find them. Your STAR stories are pre-drafted from your own experience. Your gap scripts are written for your specific vulnerabilities. Nothing generic.
This Page — Free Guide
✓ What NVIDIA looks for in any MLE
✓ Most likely questions from reported interviews
✓ General prep framework
🔒 How your background measures up
🔒 Your 12 specific questions
🔒 Scripts for your gaps
→
Your Report — Personalized
✓ Your 3 biggest red flags — identified by name
✓ Exact bridge scripts for each gap
✓ Your STAR stories pre-drafted from your resume
✓ Question types most likely for your background
✓ Your experiences mapped to NVIDIA Values
✓ Your fit score against this exact role
What's Inside Your 55-Page Report
1
Orientation
The unspoken bar NVIDIA sets — what most candidates miss before they even walk in
2
Where You Stand
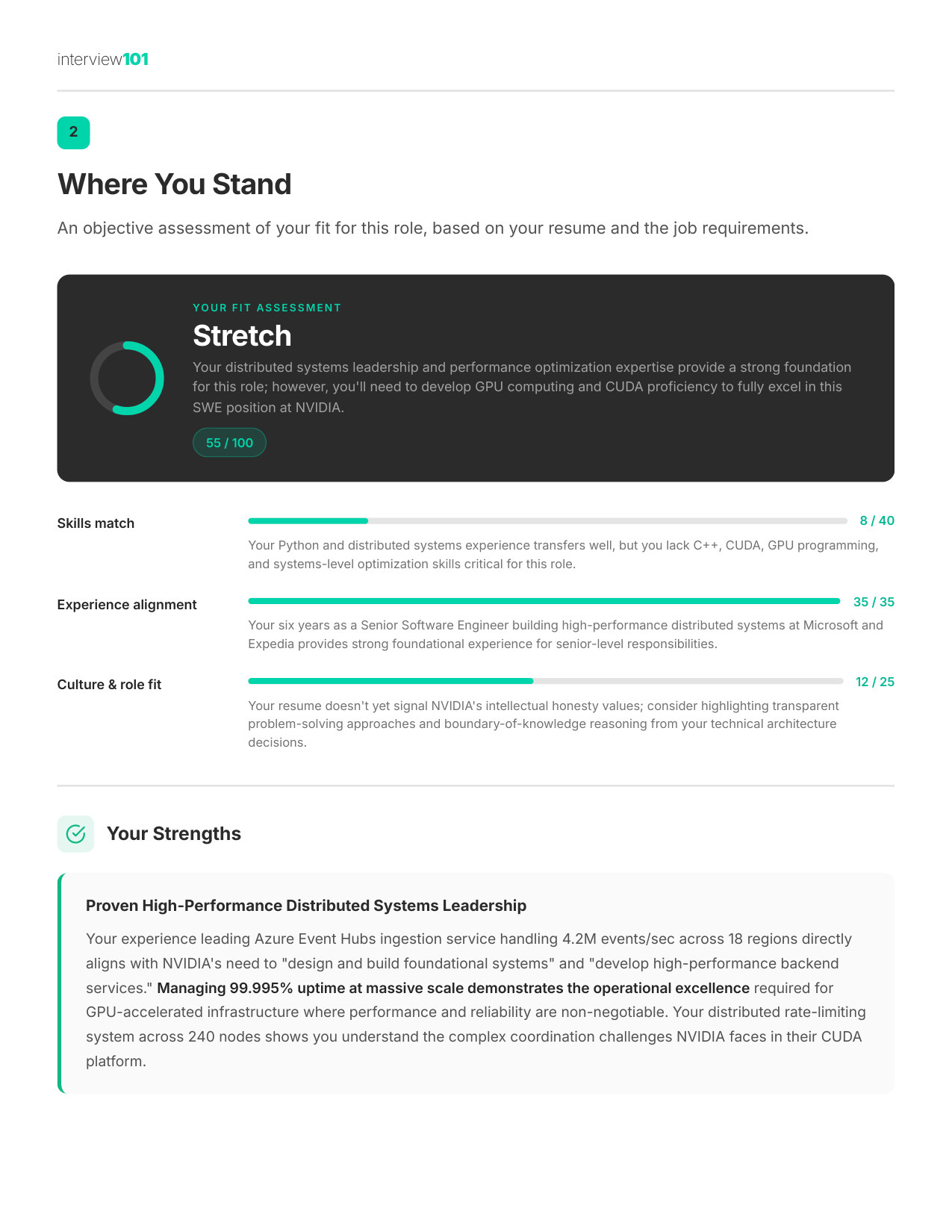
Your fit score by skill, experience, and culture fit — know your strengths before they probe your gaps
3
What They Actually Want
The real criteria interviewers score you on — beyond what the job description says
4
Your Story
Your resume reframed for NVIDIA's lens — how to position your background so it lands
5
Experience That Wins
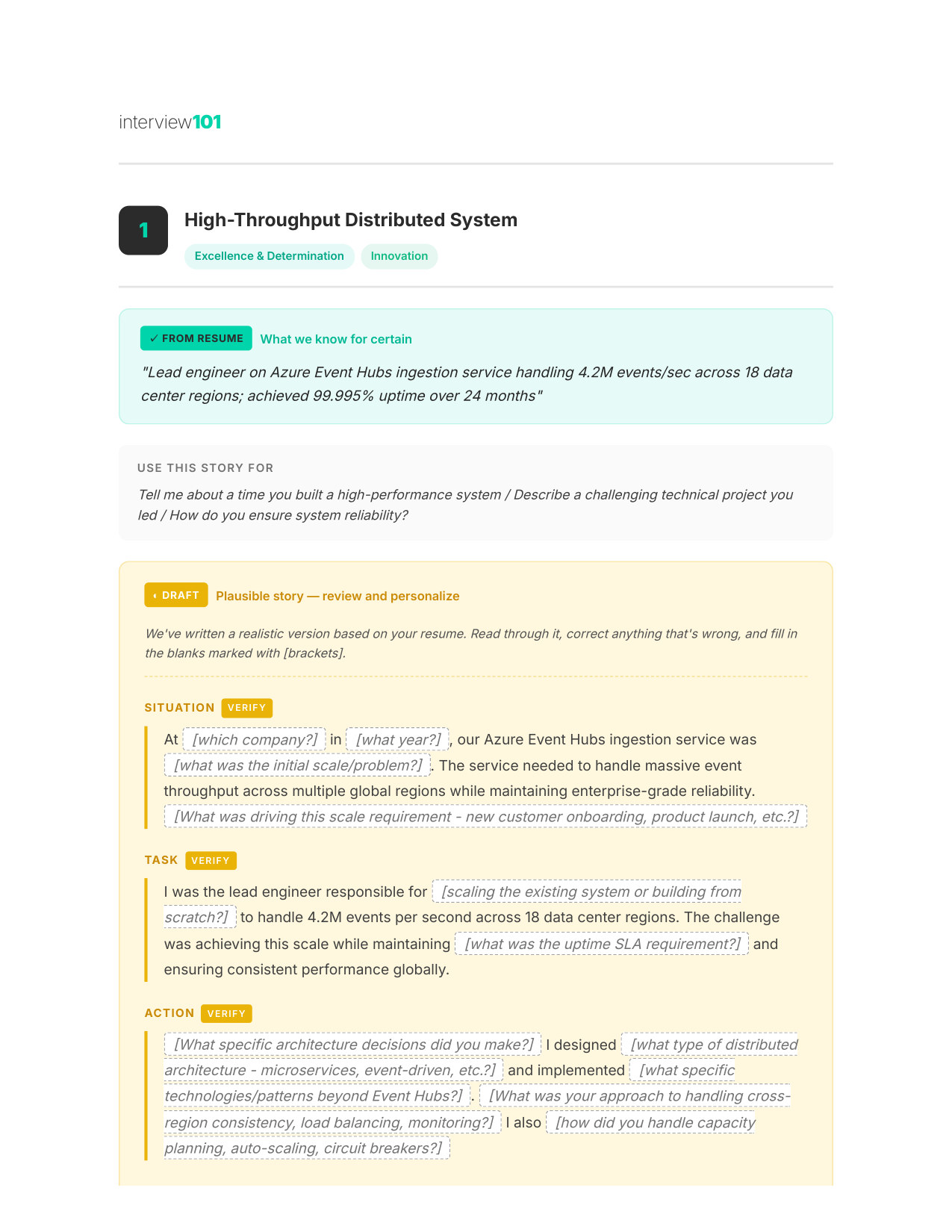
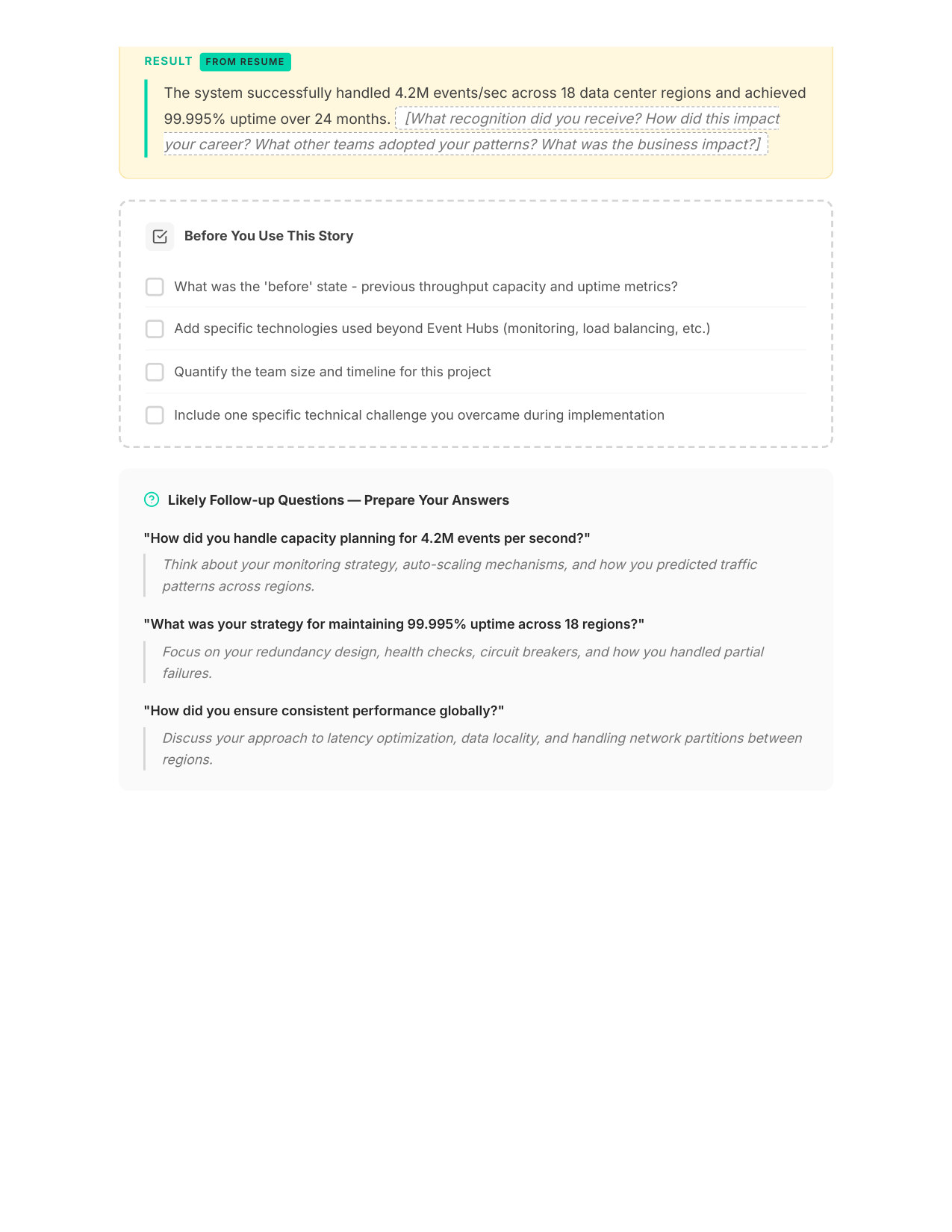
Your specific experiences mapped to the NVIDIA Values you'll face — walk in knowing which examples to use
6
Questions You Will Face
The question types most likely given your background — with what a strong answer looks like for someone in your position
7
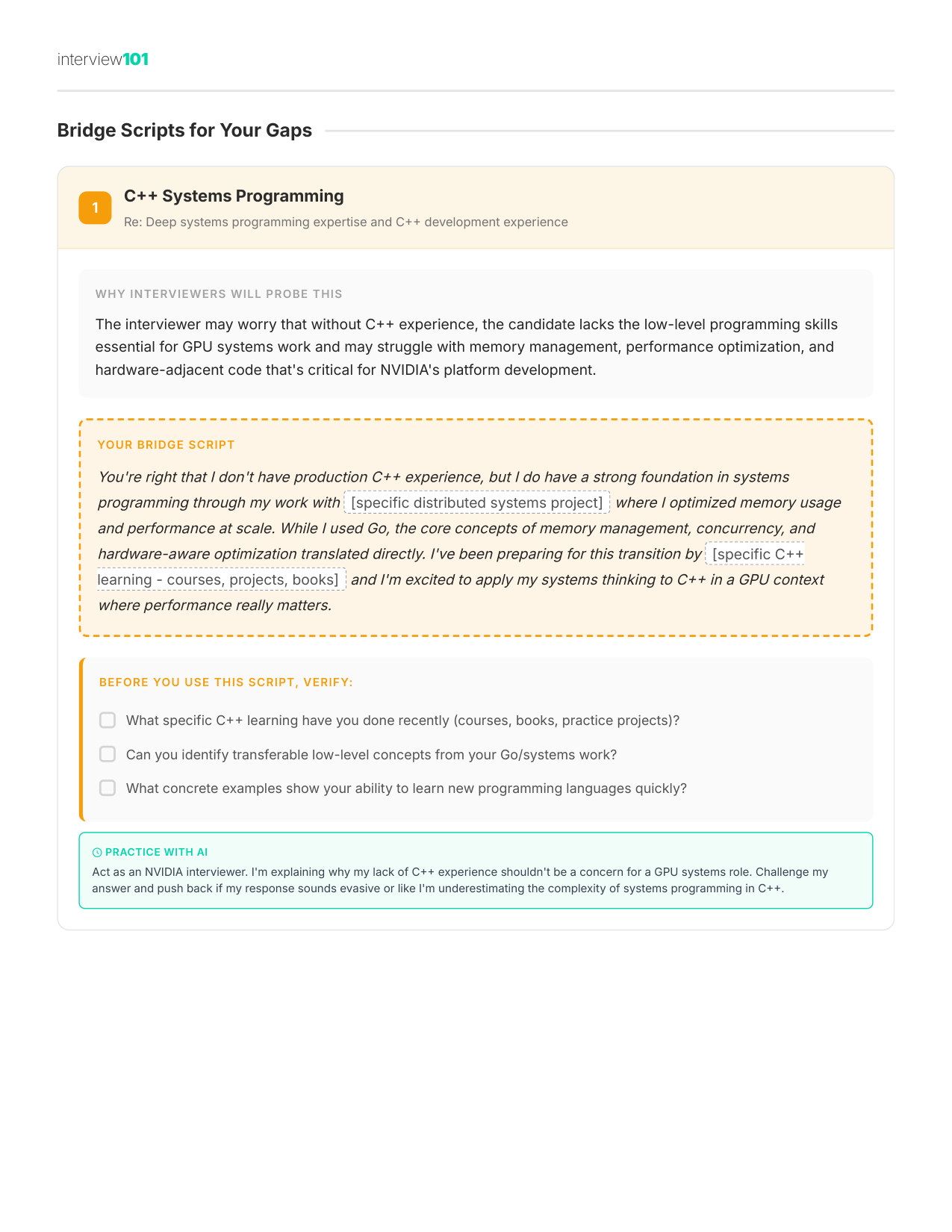
Scripts for Awkward Questions
Exact words for when they probe your weakest areas — so you do not freeze when it matters most
8
Questions to Ask Them
Sharp questions that signal preparation and seniority — and make interviewers remember you
9
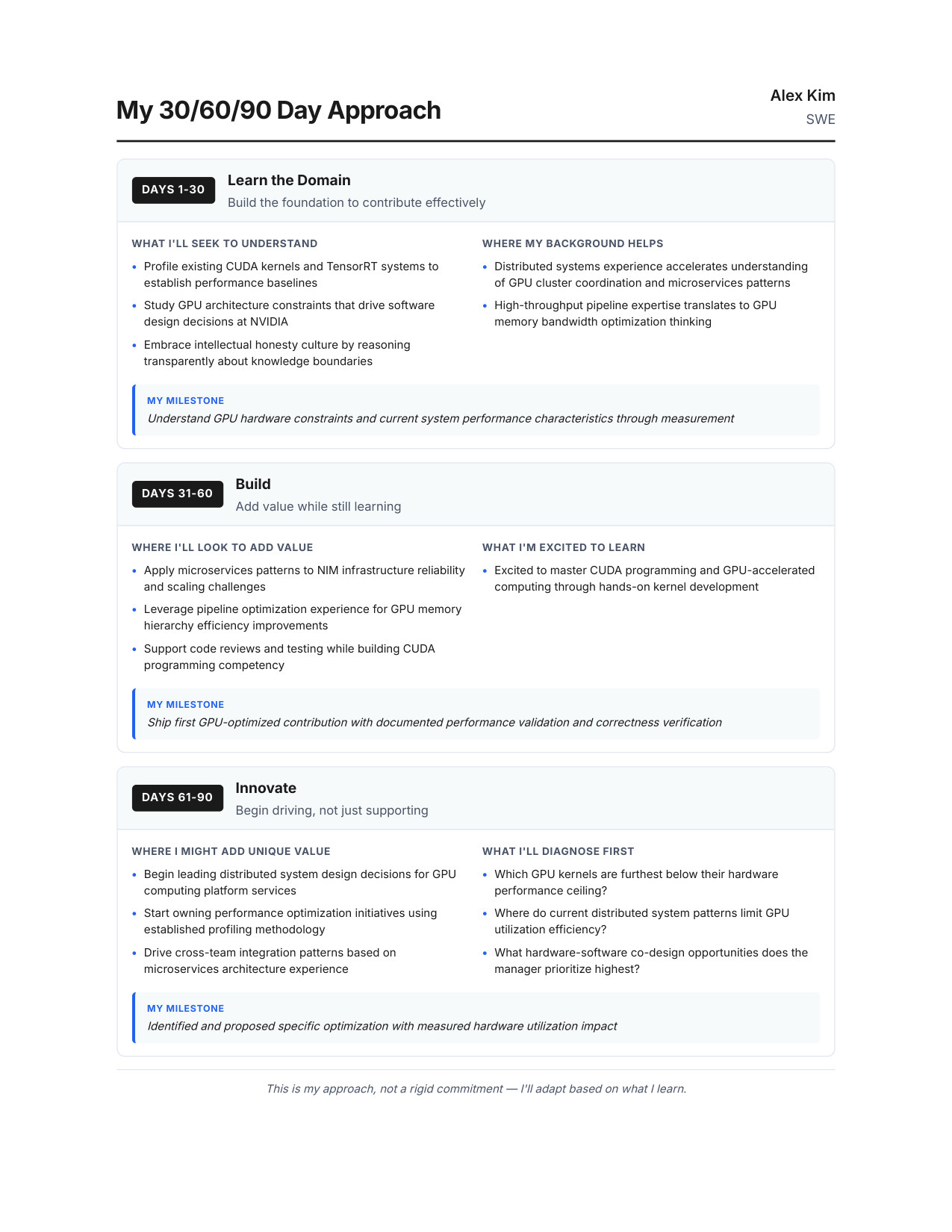
30/60/90 Day Plan
Show NVIDIA you're already thinking like an employee — demonstrates ownership from day one
10
Interview Day Cheat Sheet
One page. Everything you need. Review 5 minutes before you walk in — and walk in ready.
How It Works
1
Upload your resume + target JD
The job description you're actually applying to — not a generic one
2
We analyze your fit
Your background is scored against the NVIDIA MLE blueprint — gaps, strengths, likely questions
3
Your report arrives within 24 hours
55-page personalized PDF delivered to your inbox — ready to work through before your interview
See Inside the Report
Real pages from a NVIDIA Software Engineer report
Your MLE report follows the same structure — built entirely around your background and this role.
1 / 11Your Interview Prep Starts Here
Zoom
2 / 11Where You Stand
Zoom
3 / 11What They Actually Want
Zoom
4 / 11Your 2-Minute Pitch
Zoom
5 / 11Your STAR Story (Page 1)
Zoom
6 / 11Your STAR Story (Page 2)
Zoom
7 / 11Questions You'll Face
Zoom
8 / 11Scripts for Awkward Questions
Zoom
9 / 11Your Gap Script
Zoom
10 / 1130/60/90 Day Plan
Zoom
11 / 11Interview Day Cheat Sheet
Zoom
Download the Full Sample Report — Free
See exactly what you're buying before you commit — 50+ pages, no email required
🔒 30-day money-back guarantee — no questions asked
FAQ
Common Questions About the NVIDIA Machine Learning Engineer Interview
The NVIDIA Machine Learning Engineer interview process typically takes 3-5 weeks from application to offer. However, the process can be slower than average, with 6-10 weeks total being common, and 2+ weeks post-onsite for final decisions is normal. Always verify timeline expectations with your recruiter as it can vary by team.
NVIDIA's Machine Learning Engineer interview consists of 5 rounds: an Online Assessment (60-90 minutes), ML Depth Rounds (45-60 minutes each), a Project Portfolio Deep-dive (60 minutes), System Design (45-60 minutes), and Values Assessment (45 minutes). The specific structure can vary significantly between teams, so confirm the exact format with your recruiter.
GPU hardware awareness is the most critical preparation area for NVIDIA MLE interviews, as it's evaluated in every round and distinguishes NVIDIA from other tech companies. You should understand CUDA fundamentals, memory hierarchy, parallelization patterns, and how ML algorithms map to GPU architectures. Be prepared for deep technical discussions about your project portfolio and demonstrate intellectual honesty about your hardware-ML knowledge boundaries.
NVIDIA MLE interviews are highly technical with significant depth in GPU-aware machine learning implementation. The difficulty varies considerably by team - inference optimization roles focus on TensorRT and model optimization, while training infrastructure roles emphasize distributed systems and FSDP at scale. Expect medium-to-hard algorithm and data structure problems combined with deep ML system design questions that require GPU hardware understanding.
Yes, NVIDIA Values questions appear in every interview round alongside technical questions, rather than being isolated to dedicated behavioral rounds. The values assessment evaluates cultural fit and leadership principles throughout the technical discussions. Be prepared to demonstrate NVIDIA's values while discussing your technical work and project experiences.
Expect ML implementation-focused coding in Python rather than pure algorithmic problems, including implementing attention mechanisms from scratch, quantization algorithms, and distributed training primitives like ring AllReduce. Some roles include CUDA kernel questions requiring understanding of thread hierarchy and memory patterns. CUDA C++ may be required for roles involving direct GPU kernel work, and you should practice writing ML code without IDE support.
This page shows you what the NVIDIA Machine Learning Engineer interview looks like in general. Your personalized report shows you how to prepare specifically — using your resume, a real job description, and NVIDIA's actual evaluation criteria.
This page shows every NVIDIA MLE candidate the same thing. Your report is built around you — your resume, your gaps, your most likely questions.
What's inside: your fit score broken down by skill, experience, and culture; your top 3 risk areas by name; the 12 questions most likely for your specific background with full answer decodes; your experiences mapped to the NVIDIA Values you'll face; scripts for when they probe your weakest spots; sharp questions to ask your interviewers; and a one-page cheat sheet to review before you walk in. 55 pages. Delivered within 24 hours.
Within 24 hours. Your report is reviewed and delivered to your inbox within 24 hours of payment. Most orders arrive significantly faster. You'll receive an email with your personalized PDF as soon as it's ready.
30-day money-back guarantee, no questions asked. If your report doesn't help you feel more prepared, email us and we'll refund in full.