Recommendation System IS the Product — System Design Is the Primary Evaluation
4–8
Weeks Timeline
Application to offer
$400–650K
Total Compensation
Base + Stock + Bonus
Questions sourced from reported interviews
Every claim traced to a verified source
Updated quarterly — data stays current
2,600+ reported interviews analyzed
Self-Assessment
Is This Role Right for You?
See what Netflix looks for in Machine Learning Engineer candidates and check how you measure up.
What strong candidates bring to the role:
Strong candidates bring ownership experience across the complete ML lifecycle — training data pipelines, model architecture, offline evaluation frameworks, A/B test design, serving infrastructure, and post-launch monitoring for recommendation or personalization systems.
Strong candidates bring experience making architectural decisions for ML systems serving millions of users, with explicit understanding of retrieval vs ranking trade-offs, feature freshness implications, and online/offline metric alignment challenges.
Strong candidates bring hands-on experience with LLM training, fine-tuning, and serving at production scale, including understanding of vLLM-based inference, batching strategies, quantization techniques, and LLM evaluation infrastructure.
Strong candidates bring experience designing evaluation metrics that connect to business outcomes, understanding why offline metrics may not predict online performance, and experience with recommendation-specific metrics beyond accuracy.
What Netflix Looks For
Netflix rewards candidates who make autonomous ML architectural decisions with explicit business trade-off reasoning, not those who execute well-defined modeling tasks. The company looks for engineers who can own recommendation systems end-to-end and demonstrate candor about production failures while connecting model decisions to member engagement outcomes.
Free — Takes 60 seconds
See your personal gap risk profile
Upload your resume and your target job description. Get your fit score, your top 3 risks, and exactly what to prepare first — before you spend another hour prepping the wrong things.
Machine Learning Engineers at Netflix own the complete recommendation system lifecycle — from training data pipelines to A/B testing frameworks to serving infrastructure at 300M-member scale. Unlike other companies where MLEs focus primarily on model development, Netflix MLEs are responsible for the entire ML system architecture that powers personalization across the platform. You'll design two-tower retrieval systems, cascaded ranking models, and increasingly, GenAI-powered content understanding systems that directly impact member engagement.
What's Different at Netflix
Netflix rewards candidates who make autonomous ML architectural decisions with explicit business trade-off reasoning, not those who execute well-defined modeling tasks. The company looks for engineers who can own recommendation systems end-to-end and demonstrate candor about production failures while connecting model decisions to member engagement outcomes.
ML System Design Mastery
System design carries more weight than coding in Netflix MLE loops — the only FAANG company where this is true. You must demonstrate architectural judgment for recommendation systems at Netflix scale, including retrieval vs ranking trade-offs, feature freshness decisions, and explore vs exploit balance. Directors frequently appear in these rounds to evaluate your ML system thinking.
Take-Home Modeling Philosophy
Netflix's pre-onsite modeling quiz is unique among FAANG companies and tests how you frame recommendation problems and choose evaluation metrics. Strong candidates connect offline metrics to business outcomes and demonstrate understanding that precision@k vs NDCG matters differently depending on member engagement objectives. Treating this as a notebook exercise rather than business judgment consistently leads to poor performance.
Freedom and Responsibility Alignment
The keeper test runs throughout every round, not just behavioral interviews. Interviewers evaluate whether they would fight to keep you based on your ML architectural judgment, autonomy in decision-making, and candor about trade-offs. You must show you can identify and drive toward solutions for the most important ML problems without committee approval or excessive oversight.
Your Report Adds
Netflix's Netflix Culture Principles are mapped directly to the bullet points on your resume. You'll see exactly which ones you can claim with evidence — and which ones are gaps to address before the interview.
The Netflix Machine Learning Engineer Interview Process
The Netflix Machine Learning Engineer interview timeline varies by team — confirm the specifics with your recruiter.
Important: Netflix MLE interview loops vary by team and level — verify your specific structure with your recruiter before the first screen. The consistent elements across teams: take-home modeling quiz (unique among FAANG) assessing recommendation problem framing and metric judgment; coding screen; onsite with ML system design as the primary and highest-weighted round, behavioral/culture (keeper-test throughout), and coding (secondary weight). Directors frequently appear in onsite loops — unique to Netflix. The take-home quiz is not a formality: candidates who treat it like a notebook exercise rather than a business judgment exercise consistently underperform. Freedom and Responsibility is evaluated in every round, not just a dedicated behavioral session.
1
Initial Screen
45-60 min
Recruiter conversation covering background, interest in Netflix culture, and basic technical screening. May include high-level ML system design discussion.
Evaluates
Culture fit assessmenttechnical communicationrole alignment
2
Take-Home Modeling Quiz
3-5 days
Unique to Netflix among FAANG — recommendation problem requiring metric selection, evaluation framework design, and business objective reasoning. Not a coding exercise.
Evaluates
Business judgmentrecommendation problem framingmetric selection rationale
3
Coding Interview
45-60 min
Python-focused ML implementation problems like similarity functions, recommendation metrics, or collaborative filtering algorithms. Some roles include Spark/PySpark.
Evaluates
ML coding abilityPython proficiencyclean code without IDE support
4
Onsite Loop
4-5 hours
Multiple rounds including ML system design (primary evaluation), behavioral/culture (Freedom and Responsibility), additional coding, and ML depth. Directors often participate.
Evaluates
ML system architecturekeeper test alignmentautonomous judgmenttechnical depth
Round Breakdown — Machine Learning Engineer
Coding Ml Python
17%
Ml System Design
25%
Behavioral Culture
33%
Ml Depth And Modeling
25%
Your Report Adds
Your report includes a stage-by-stage prep checklist built around your background — what to emphasize in each round, based on the specific gaps between your resume and this role.
At Netflix, every Machine Learning Engineer candidate is evaluated against their Netflix Culture Principles. Expand each one below to see what interviewers are actually looking for.
Technical EvaluationAssessed alongside Netflix Culture Principles in every round
End-to-End Recommendation System Experience
Strong candidates bring ownership experience across the complete ML lifecycle — training data pipelines, model architecture, offline evaluation frameworks, A/B test design, serving infrastructure, and post-launch monitoring for recommendation or personalization systems.
ML System Architecture at Scale
Strong candidates bring experience making architectural decisions for ML systems serving millions of users, with explicit understanding of retrieval vs ranking trade-offs, feature freshness implications, and online/offline metric alignment challenges.
Production GenAI Implementation
Strong candidates bring hands-on experience with LLM training, fine-tuning, and serving at production scale, including understanding of vLLM-based inference, batching strategies, quantization techniques, and LLM evaluation infrastructure.
Business-Connected ML Evaluation
Strong candidates bring experience designing evaluation metrics that connect to business outcomes, understanding why offline metrics may not predict online performance, and experience with recommendation-specific metrics beyond accuracy.
All Netflix Culture Principles — click any to see how to demonstrate it
Netflix requires MLEs to demonstrate end-to-end ownership of recommendation systems, not just model training. This means you've built the infrastructure that gets models from research to production at scale. Netflix evaluates whether you understand the full product lifecycle from data ingestion to user impact measurement, treating ML as a product engineering discipline rather than pure research.
How to Demonstrate: Walk through a specific system where you owned multiple components — describe how your data pipeline decisions affected model quality, how your offline evaluation framework connected to business metrics, and how you designed A/B tests to measure actual user engagement. Netflix interviewers probe for evidence you've debugged production serving issues, not just trained models. They want to hear about trade-offs you made between model complexity and serving latency, or how you designed monitoring that caught model drift before it affected user experience.
Netflix prioritizes architectural reasoning over implementation details in MLE interviews. They want to see you make ML system design decisions based on business constraints, user behavior, and scale requirements rather than following industry patterns blindly. Netflix system design carries more weight than coding because they need MLEs who can architect solutions for their unique streaming and recommendation challenges.
How to Demonstrate: When discussing architecture choices, always connect decisions to Netflix's specific constraints — explain why you'd choose cascaded ranking for cold-start users but single-stage for engaged users, or why real-time features matter more for trending content than catalog browsing. Netflix interviewers expect you to reason through trade-offs like model complexity versus interpretability for recommendation explanations, or batch versus streaming feature computation based on content consumption patterns. They're looking for evidence you understand the 'why' behind each architectural pattern, not just the 'what.'
Netflix values MLEs who think beyond academic metrics to business impact measurement. They expect candidates to understand that model performance must translate to user engagement, retention, and viewing time — not just mathematical optimization. Netflix's take-home assignments evaluate whether you can design evaluation frameworks that predict real-world recommendation performance.
How to Demonstrate: Discuss specific metric choices tied to business objectives — explain why you'd optimize for precision@k when focusing on user satisfaction but NDCG when measuring content diversity. Netflix wants to hear how you've dealt with offline-online metric gaps, like when your offline AUC improved but A/B test click-through rates stayed flat. Describe evaluation frameworks where you measured both immediate engagement and longer-term retention, and how you balanced competing objectives like user satisfaction versus content diversity in your metric design.
Netflix is heavily investing in GenAI infrastructure for recommendation and content applications, requiring MLEs who understand production LLM deployment at streaming scale. They're building systems for LLM-based content understanding, personalized content generation, and recommendation feature extraction. Netflix expects candidates to be current on production GenAI challenges, not just research trends.
How to Demonstrate: Discuss practical LLM deployment considerations like vLLM optimization for recommendation serving latency, or how you'd design batching strategies for content embedding generation at Netflix's catalog scale. Netflix interviewers want to hear about fine-tuning trade-offs — when you'd choose LoRA for recommendation feature extraction versus full fine-tuning for content understanding, and how you'd evaluate LLM-generated features against traditional collaborative filtering. Show awareness of multi-modal challenges in video content understanding and how LLM evaluation differs from traditional ML metrics when generating personalized content descriptions.
Netflix's keeper-test culture requires MLEs who can identify high-impact problems and drive solutions independently without extensive process or approval chains. They value candidates who can operate in ambiguous environments where the problem definition isn't clear and the solution approach isn't predetermined. Netflix expects MLEs to make architectural decisions quickly and take ownership of outcomes.
How to Demonstrate: Describe situations where you identified an important ML problem that wasn't officially prioritized and drove it to completion without waiting for formal approval. Netflix wants examples of you making significant architectural decisions under uncertainty — like choosing between competing recommendation approaches when business requirements were unclear, or redesigning a model architecture because you recognized performance issues before they became critical. They're looking for evidence you can operate effectively when success metrics aren't well-defined and you need to balance multiple stakeholder perspectives without explicit guidance.
Netflix's culture of candor requires MLEs to be intellectually honest about what didn't work and why. They value learning from failures more than perfect track records, expecting candidates to analyze their mistakes thoughtfully and adjust their approach permanently. Netflix interviewers probe for evidence of self-reflection and continuous improvement in technical decision-making.
How to Demonstrate: Share specific examples of models or architectures that failed despite looking promising offline — explain the gap between your offline evaluation and online results, and what you learned about evaluation design or user behavior. Netflix wants to hear how failure changed your approach permanently — like how a failed recommendation model taught you to weight certain engagement signals differently, or how a serving architecture choice that caused latency issues influenced all your subsequent system designs. They're evaluating your ability to admit mistakes clearly, analyze root causes systematically, and incorporate learnings into future decisions.
Your Report Adds
Your report scores you against each of these criteria using your resume and the job description — you get a ranked list of where you're strong vs. where you need to build a case before your interview.
Showing 12 questions drawn from 2,600+ reported interviews — ranked by frequency for Netflix Machine Learning Engineer candidates.
Your report selects the 12 questions you're most likely to face based on your resume.
Get yours →
Coding2 questions
"Implement a function that calculates Precision@K and NDCG@K for a recommendation system. Given a list of recommended item IDs and a list of relevant item IDs for a user, return both metrics. Then explain when you'd choose one metric over the other for optimizing Netflix's homepage recommendations."
Coding
· Reported 28 times
What they're really asking
Netflix evaluates whether you understand that recommendation metrics connect to business outcomes, not just mathematical correctness. They're testing if you can articulate why NDCG matters for long-term engagement while Precision@K drives immediate click-through, and whether you choose metrics that align with Netflix's dual optimization goals.
What Great Looks Like
Clean implementation with proper ranking consideration for NDCG, explicit explanation that Precision@K optimizes for immediate relevance while NDCG@K accounts for position bias and graded relevance. Connects metric choice to Netflix's business context: Precision@K for title discovery, NDCG@K for session-level satisfaction.
What Bad Looks Like
Correct implementation but treats metrics as interchangeable or purely mathematical. Doesn't connect metric choice to user behavior patterns or business outcomes. Generic explanation that could apply to any recommendation system.
"Write a Python function that implements collaborative filtering using cosine similarity for user-item recommendations. Given a user-item interaction matrix (sparse), recommend top-N items for a target user. Include handling for cold-start users and explain your approach to scaling this for Netflix's member base."
Coding
· Reported 24 times
What they're really asking
Netflix tests whether you understand that collaborative filtering is foundational to their recommendation stack but requires sophisticated engineering for production scale. They're evaluating your awareness of memory constraints, sparse matrix efficiency, and cold-start strategies that matter at 300M+ member scale.
What Great Looks Like
Efficient sparse matrix implementation using scipy.sparse, explicit cold-start handling with content-based fallback or popularity baseline. Discusses scaling challenges: approximate nearest neighbors, user clustering, or matrix factorization for production deployment at Netflix scale.
What Bad Looks Like
Dense matrix implementation that doesn't scale beyond toy datasets. No consideration of cold-start problem or computational complexity. Treats collaborative filtering as a standalone solution rather than part of a larger recommendation architecture.
System Design3 questions
"Design the ML infrastructure for Netflix's A/B testing platform that continuously evaluates recommendation model improvements. Your system needs to support running 100+ concurrent experiments across different surfaces (homepage, search, continue watching) while maintaining statistical rigor and member experience consistency."
System Design
· Reported 31 times
What they're really asking
Netflix evaluates whether you understand that A/B testing for ML systems requires sophisticated feature assignment, metric computation pipelines, and interaction effect detection. They're testing your grasp of experimentation at scale: traffic splitting, guardrail metrics, and the challenge of measuring long-term engagement changes from ML model updates.
"Design a feature store architecture that supports both Netflix's recommendation model training (batch processing of member viewing history) and real-time inference (sub-200ms P99 for homepage personalization). Address feature freshness trade-offs and scale for 300M+ members with 1B+ viewing events daily."
System Design
· Reported 29 times
What they're really asking
Netflix tests whether you understand the fundamental tension between feature freshness and serving latency in recommendation systems. They're evaluating your architectural judgment about when to pre-compute features vs compute real-time, and how to design systems that balance model accuracy with infrastructure cost at Netflix's scale.
"Design a GenAI-powered content understanding system that generates embeddings for Netflix's catalog of 15K+ titles to improve recommendation relevance. Your system needs to process new content releases, handle multi-modal inputs (video, audio, metadata, subtitles), and serve embeddings for downstream ML models."
System Design
· Reported 22 times
What they're really asking
Netflix evaluates whether you understand that GenAI in production requires sophisticated infrastructure for multi-modal processing and embedding serving at scale. They're testing your awareness of Netflix's active GenAI infrastructure investments and whether you can design systems that integrate LLM-based content understanding with existing recommendation pipelines.
"Tell me about a time when you had to make a significant ML architecture decision without committee approval or clear management direction. What was the technical decision, how did you evaluate the trade-offs, and what was the outcome?"
BehavioralFreedom and Responsibility
· Reported 35 times
What they're really asking
Netflix evaluates whether you demonstrate autonomous architectural judgment rather than task execution. They're testing if you can make ML technical decisions independently, own the outcomes fully, and operate effectively under ambiguity — core to Netflix's Freedom and Responsibility culture for keeper-test MLEs.
"Describe a situation where your recommendation model or ML system failed to achieve the expected business outcome despite strong offline metrics. How did you diagnose the issue and what did you change permanently as a result?"
BehavioralCandor
· Reported 32 times
What they're really asking
Netflix tests whether you demonstrate intellectual honesty about ML failures and can articulate clear reasoning about online/offline metric disconnects. They're evaluating if you can be candid about what went wrong and show permanent learning, which is essential for Netflix's culture of honest feedback and continuous improvement.
"Walk me through a time when you identified the most important ML problem in your domain and drove toward a solution without being asked. What made you recognize this as the priority, and how did you approach solving it?"
BehavioralFreedom and Responsibility
· Reported 30 times
What they're really asking
Netflix evaluates whether you can independently identify high-impact ML problems and drive solutions proactively. They're testing if you demonstrate the keeper-test mentality of taking ownership for business outcomes and working autonomously to solve important problems, not just responding to assigned tasks.
"Tell me about a time when you had to make an ML architectural trade-off that involved accepting lower model accuracy to achieve better business outcomes. How did you make that decision and communicate it to stakeholders?"
BehavioralJudgment
· Reported 27 times
What they're really asking
Netflix tests whether you understand that ML success is measured by business impact, not just technical metrics. They're evaluating if you can make sophisticated trade-offs between model performance and practical considerations like latency, cost, or user experience — essential for Netflix's focus on member satisfaction over pure technical optimization.
"Explain the architectural differences between two-tower retrieval and matrix factorization for Netflix's recommendation system. When would you choose each approach, and how do their computational trade-offs impact serving latency at 300M+ member scale?"
Ml Depth
· Reported 26 times
What they're really asking
Netflix evaluates whether you understand that recommendation architecture choices have explicit business and infrastructure trade-offs, not just technical differences. They're testing if you can reason about why each approach exists in Netflix's context and make architectural decisions based on scale, latency, and business requirements.
"How would you design an evaluation framework for Netflix's recommendation system that predicts online A/B test outcomes from offline metrics? Address the challenge that offline NDCG improvements don't always translate to online engagement gains."
Ml Depth
· Reported 23 times
What they're really asking
Netflix tests whether you understand that offline evaluation is a design challenge, not a solved problem. They're evaluating if you recognize that traditional ML metrics often fail to predict real user behavior and whether you can design evaluation approaches that better connect to Netflix's business outcomes.
"Describe how you would implement and evaluate a fine-tuning strategy for LLM-based content understanding at Netflix scale. Compare LoRA/PEFT approaches vs full fine-tuning for extracting recommendation features from video content and metadata."
Ml Depth
· Reported 19 times
What they're really asking
Netflix evaluates whether you understand the practical considerations of LLM deployment in production recommendation systems. They're testing your knowledge of Netflix's active GenAI infrastructure work and whether you can make informed trade-offs between fine-tuning approaches based on scale, cost, and recommendation quality requirements.
These are the questions Netflix Machine Learning Engineer candidates report facing most. Your report takes it further — 12 questions matched to your resume, with what great looks like, red flags to avoid, and which of your experiences to use for each one.
Your report selects 12 questions ranked by likelihood given your specific profile — and for each one, identifies the story from your resume you should tell and the angle most likely to land with Netflix's interviewers.
How to Prepare for the Netflix Machine Learning Engineer Interview
A structured prep framework based on how Netflix actually evaluates Machine Learning Engineer candidates. Work through these focus areas in order — how much time you spend on each depends on your timeline and starting point.
Phase 1: Understand the Game
Before you prep anything, understand how Netflix actually evaluates you
Learn how Netflix's Netflix Culture Principles work in practice — not as corporate values, but as the actual rubric interviewers use to score you
Understand that two evaluation tracks run simultaneously in every interview: technical depth and Netflix Culture Principles. Most candidates over-index on one
Learn what the Recommendation System IS the Product — System Design Is the Primary Evaluation process means and how it changes the interview dynamic
Build the technical competency Netflix expects for this role
Master ML system design for recommendation systems — two-tower retrieval, cascaded ranking, feature stores, and A/B testing infrastructure at 300M-member scale
Practice business-grounded evaluation metric selection — when to use precision@k vs NDCG vs engagement metrics, and how offline metrics connect to online business outcomes
Implement recommendation algorithms and similarity functions in Python without IDE support — collaborative filtering, cosine similarity, and session detection logic
Study GenAI production challenges — LLM serving with vLLM, fine-tuning trade-offs, embedding similarity search, and RAG pipeline architecture
Review Netflix's recommendation architecture decisions — explore vs exploit balance, real-time vs batch feature freshness, and content understanding systems
Practice explaining your approach while you solve, not after. Interviewers score your process, not just the answer
Phase 3: Netflix Culture Principles Preparation
Not a separate "behavioral round" — woven into every interview
Netflix Culture Principles evaluation runs throughout every interview round — ML system design rounds assess autonomous architectural judgment, coding rounds evaluate candor about trade-offs, and the take-home quiz specifically tests business acumen in recommendation problem framing.
Build 2–3 strong experiences per Netflix Culture Principles principle — not one per principle
Each experience needs a measurable outcome. Quantify impact wherever possible — business results, scale, adoption, or efficiency gains with real numbers
Your experiences must be real and traceable to your actual background. Interviewers probe deeply — vague or fabricated stories fall apart under follow-up questions
Focus first on the most frequently tested principles for this role: Recommendation system ownership — show you have owned the full recommendation or personalization ML lifecycle: training data pipeline, model architecture, offline evaluation framework, A/B test design, serving infrastructure, and post-launch monitoring; Netflix MLEs who only describe model training without owning the system around it are not meeting the bar, System design judgment over coding correctness — show you make ML architectural decisions (two-tower vs matrix factorization vs LLM-based retrieval; cascaded ranking vs single-stage; batch vs real-time feature freshness) with explicit business trade-off reasoning, not just because a pattern is standard; Netflix system design interviewers probe whether you understand why each architectural choice exists, not just whether you can name it, Take-home modeling philosophy — show you choose evaluation metrics that connect to business outcomes, not just model accuracy; for recommendation problems, this means understanding that precision@k matters differently than NDCG depending on the business objective, and that offline metrics predicting online outcomes is a design challenge, not a given
Phase 4: Integration
The phase most candidates skip — and most regret
Practice integrated ML system design scenarios followed immediately by Freedom and Responsibility behavioral questions about the architectural decisions you just made, simulating how Netflix evaluates keeper-test alignment through technical judgment.
Practice out loud, timed, from start to finish. Silent practice does not prepare you for the pressure of speaking under scrutiny
Identify your weakest Netflix Culture Principles area and your weakest technical area. Spend disproportionate final-week time there — interviewers will probe your gaps
Do a full dry-run 2–3 days before your interview. Not the day before — you need time to course-correct
Netflix-Specific Tip
Netflix rewards candidates who make autonomous ML architectural decisions with explicit business trade-off reasoning, not those who execute well-defined modeling tasks. The company looks for engineers who can own recommendation systems end-to-end and demonstrate candor about production failures while connecting model decisions to member engagement outcomes.
Watch Out For This
“Your personalized homepage recommendation model passed offline evaluation with a 3% NDCG improvement but online A/B test shows a 2% drop in long-term engagement after 2 weeks, despite an initial click-through lift. Walk me through how you diagnose and respond to this.”
This is Netflix's canonical MLE production scenario — the online/offline metric gap is one of the most common and consequential failures in recommendation systems, and Netflix's long-term engagement business model makes it especially important. The question tests four simultaneous dimensions: diagnostic sophistication (can you identify the specific failure class from training/serving skew, feedback loop reinforcement, or metric gaming?); business understanding (why does a click-through lift that reverses long-term engagement represent a system failure, not a success?); experimentation design (what does your holdout and long-run metric measurement look like for a recommendation change?); and permanent fix ownership (what architectural change prevents the next model from optimizing for short-term clicks at the expense of long-term trust?). Candidates who only describe the serving skew diagnostic without addressing the business implication of the engagement drop and the architectural fix reveal they are treating recommendations as an optimization problem, not a product.
Your report includes the full answer framework for this question and Netflix's other curveball questions — mapped to your specific background.
This plan works for any Netflix Machine Learning Engineer candidate.
Your report makes it specific to you — the exact gaps in your background, the exact questions your resume makes likely, and a clear picture of exactly what to focus on given your specific risks.
Your report includes 8 stories pre-drafted from your resume, each mapped to a specific Netflix Netflix Culture Principles and competency. You practice answers — you don't write them from scratch the week before your interview.
You've worked too hard for your resume to fail the Netflix MLE interview. Walk in knowing your 3 biggest red flags — and exactly what to say when they surface.
Not hoping you prepared the right things. Knowing.
Your report starts with your resume, scores you against this exact role, and tells you which Netflix Culture Principles you can prove with evidence — and which ones Netflix will probe. Then it shows you exactly what to do about the gaps before they find them. Your STAR stories are pre-drafted from your own experience. Your gap scripts are written for your specific vulnerabilities. Nothing generic.
This Page — Free Guide
✓ What Netflix looks for in any MLE
✓ Most likely questions from reported interviews
✓ General prep framework
🔒 How your background measures up
🔒 Your 12 specific questions
🔒 Scripts for your gaps
→
Your Report — Personalized
✓ Your 3 biggest red flags — identified by name
✓ Exact bridge scripts for each gap
✓ Your STAR stories pre-drafted from your resume
✓ Question types most likely for your background
✓ Your experiences mapped to Netflix Culture Principles
✓ Your fit score against this exact role
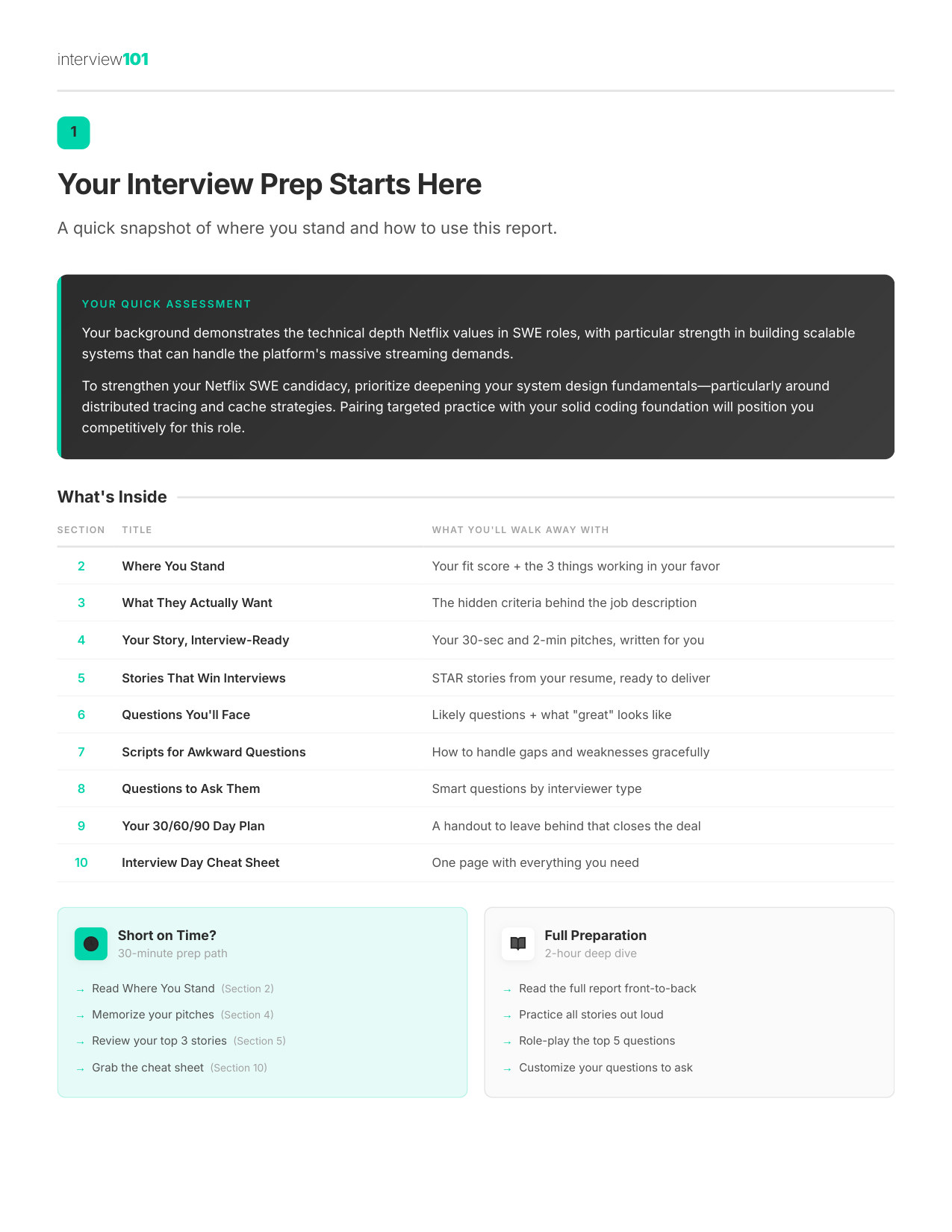
What's Inside Your 55-Page Report
1
Orientation
The unspoken bar Netflix sets — what most candidates miss before they even walk in
2
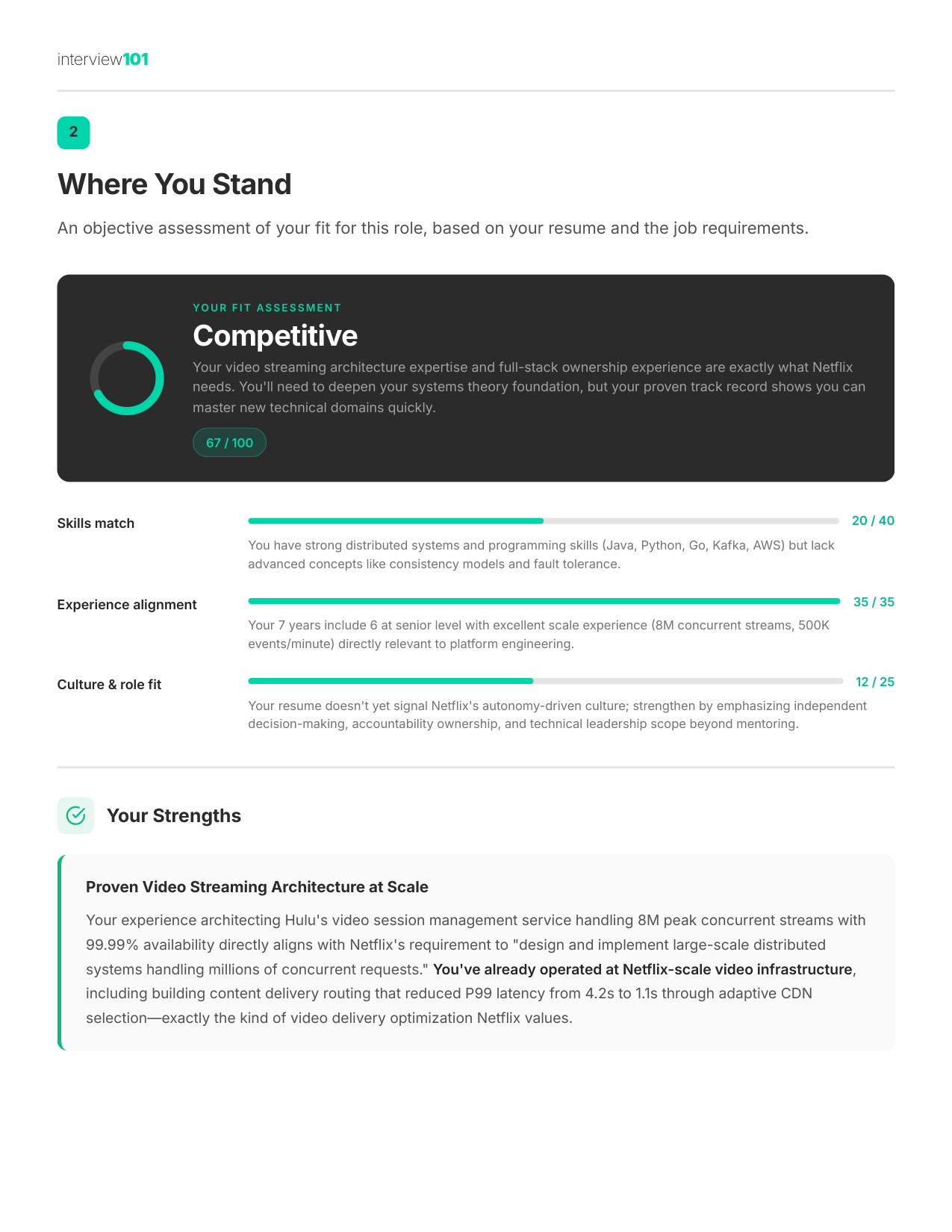
Where You Stand
Your fit score by skill, experience, and culture fit — know your strengths before they probe your gaps
3
What They Actually Want
The real criteria interviewers score you on — beyond what the job description says
4
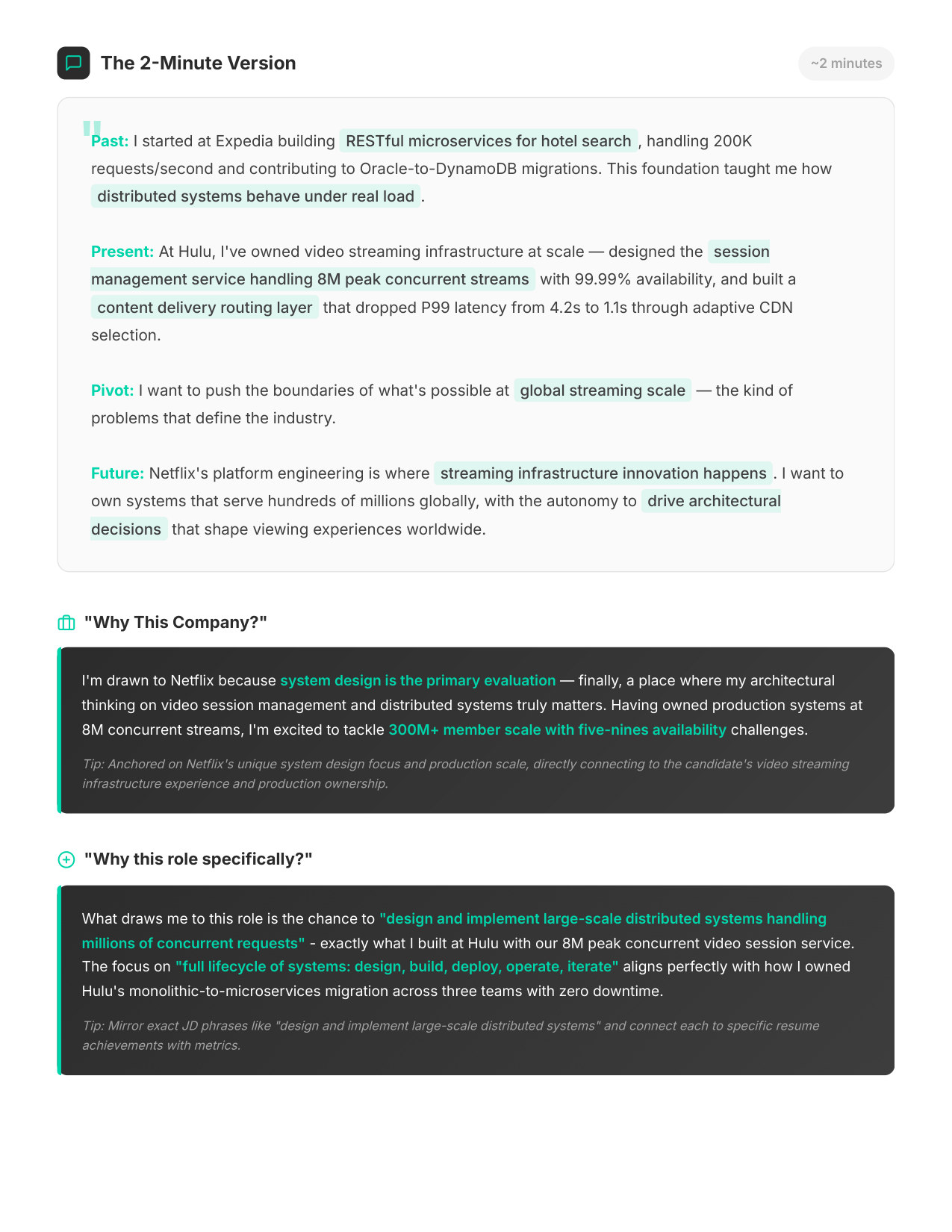
Your Story
Your resume reframed for Netflix's lens — how to position your background so it lands
5
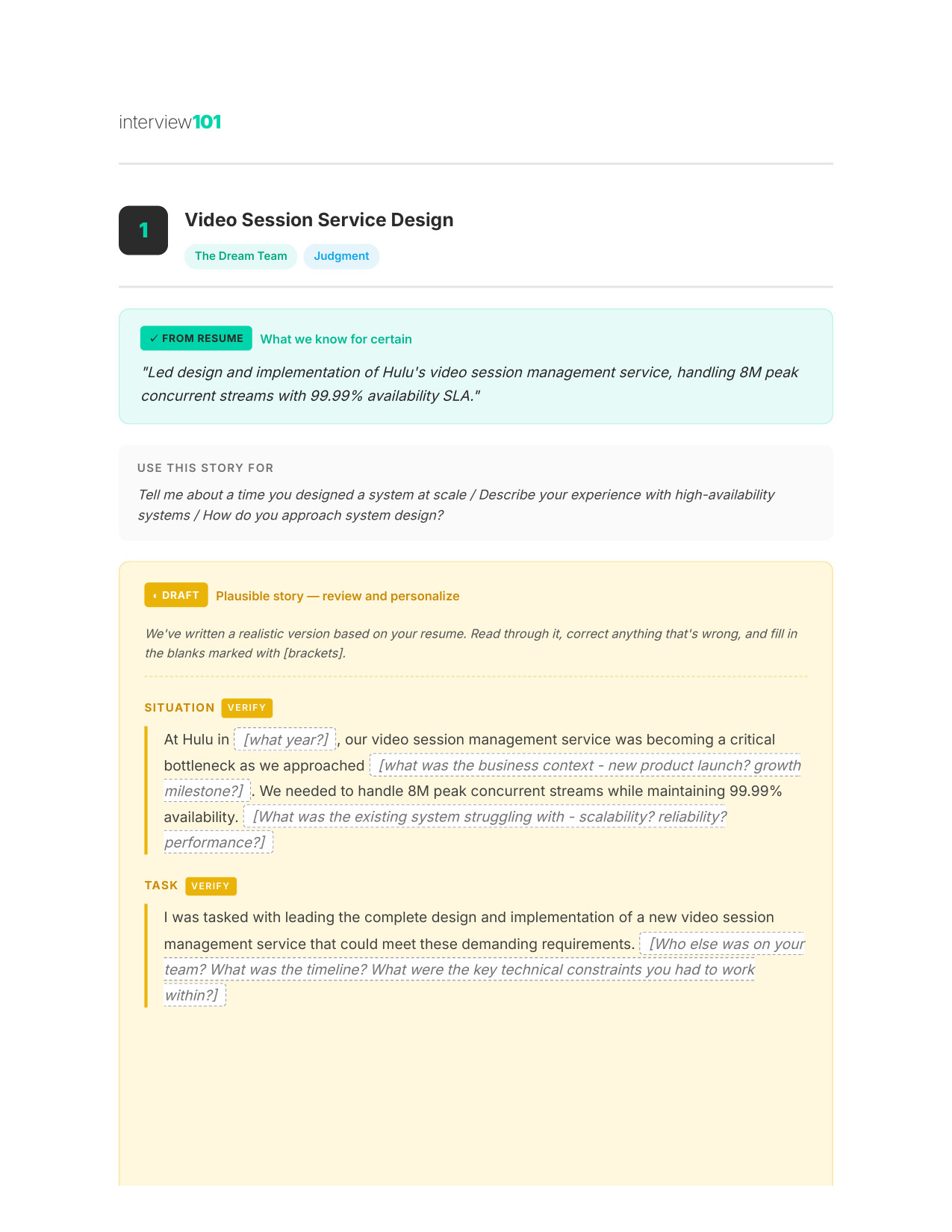
Experience That Wins
Your specific experiences mapped to the Netflix Culture Principles you'll face — walk in knowing which examples to use
6
Questions You Will Face
The question types most likely given your background — with what a strong answer looks like for someone in your position
7
Scripts for Awkward Questions
Exact words for when they probe your weakest areas — so you do not freeze when it matters most
8
Questions to Ask Them
Sharp questions that signal preparation and seniority — and make interviewers remember you
9
30/60/90 Day Plan
Show Netflix you're already thinking like an employee — demonstrates ownership from day one
10
Interview Day Cheat Sheet
One page. Everything you need. Review 5 minutes before you walk in — and walk in ready.
How It Works
1
Upload your resume + target JD
The job description you're actually applying to — not a generic one
2
We analyze your fit
Your background is scored against the Netflix MLE blueprint — gaps, strengths, likely questions
3
Your report arrives within 24 hours
55-page personalized PDF delivered to your inbox — ready to work through before your interview
See Inside the Report
Real pages from a Netflix Software Engineer report
Your MLE report follows the same structure — built entirely around your background and this role.
1 / 11Your Interview Prep Starts Here
Zoom
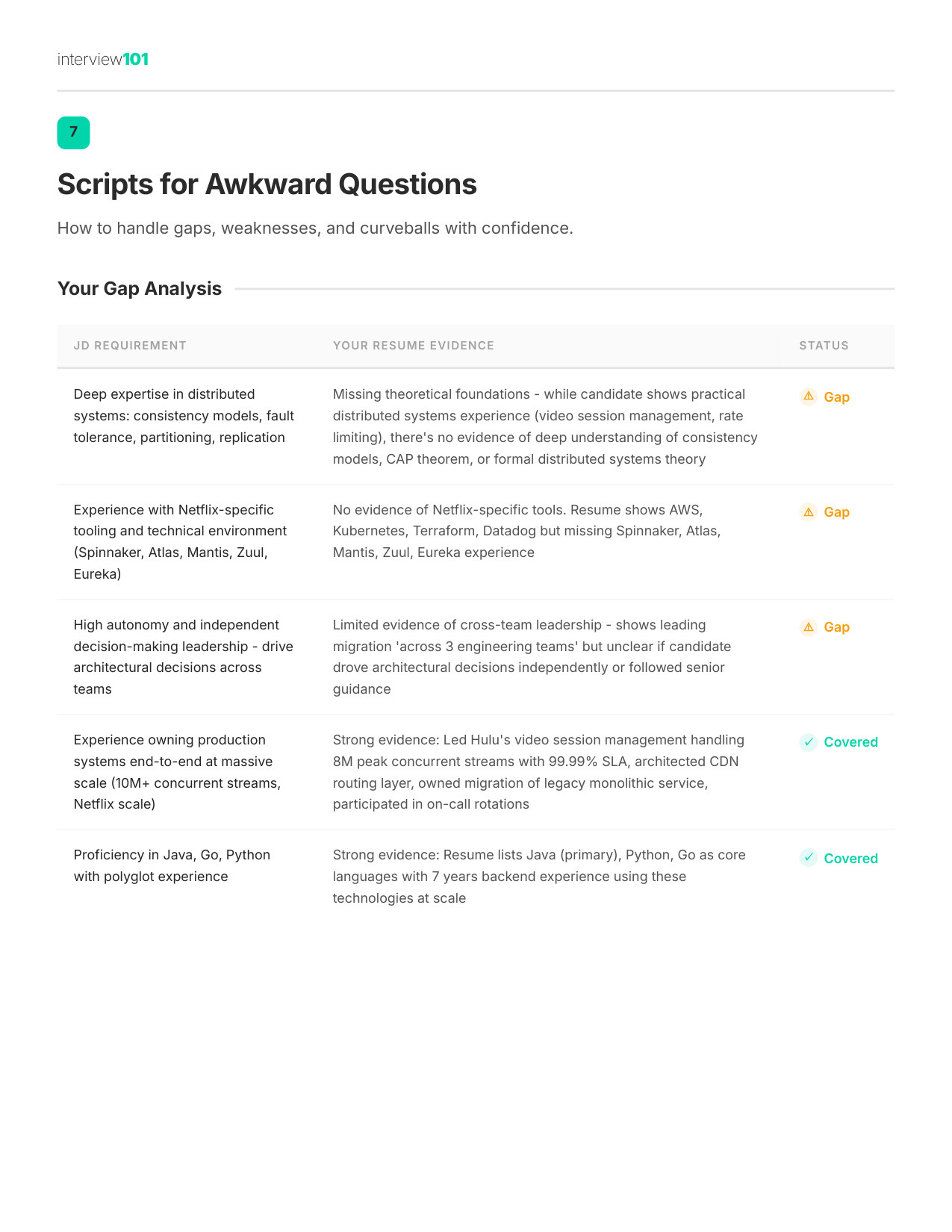
2 / 11Where You Stand
Zoom
3 / 11What They Actually Want
Zoom
4 / 11Your 2-Minute Pitch
Zoom
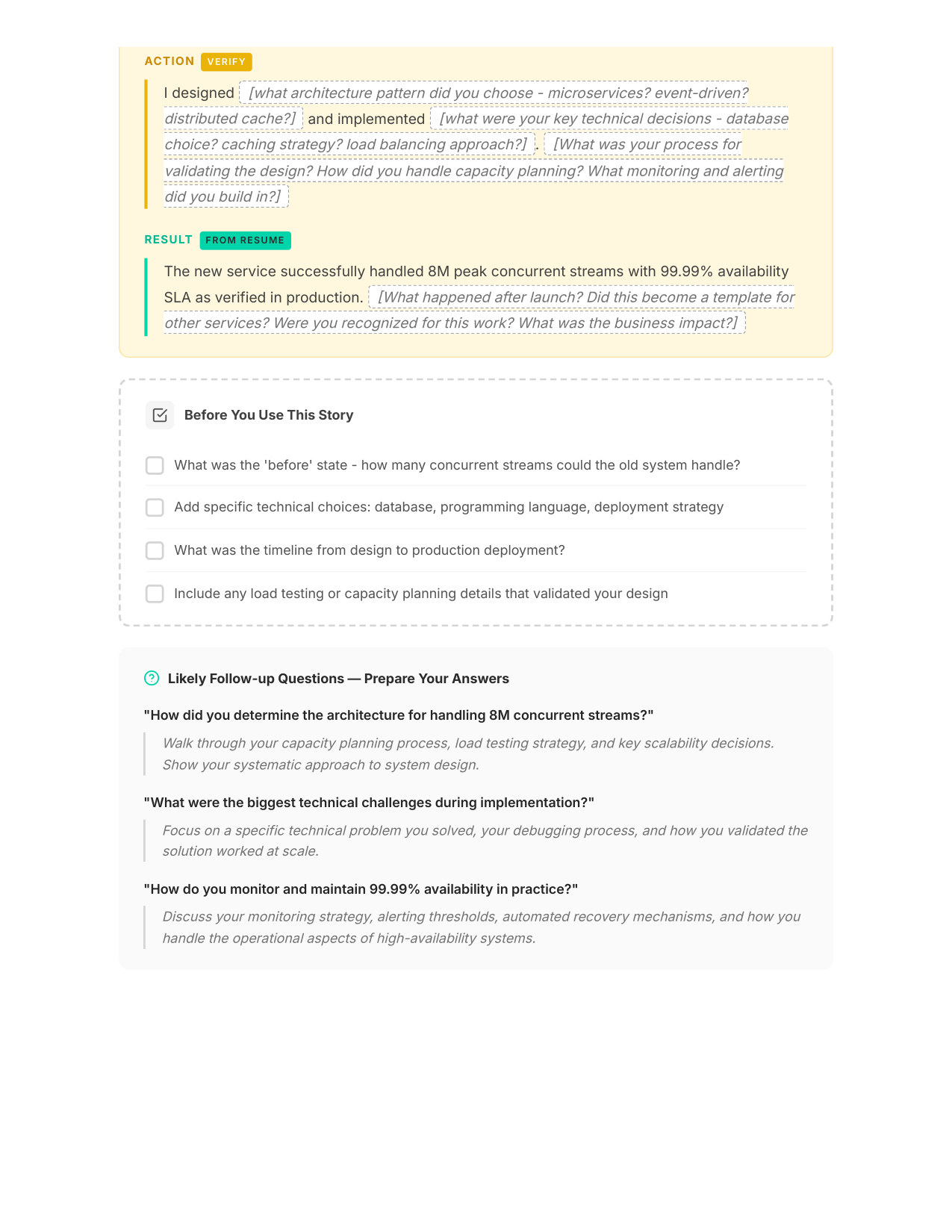
5 / 11Your STAR Story (Page 1)
Zoom
6 / 11Your STAR Story (Page 2)
Zoom
7 / 11Questions You'll Face
Zoom
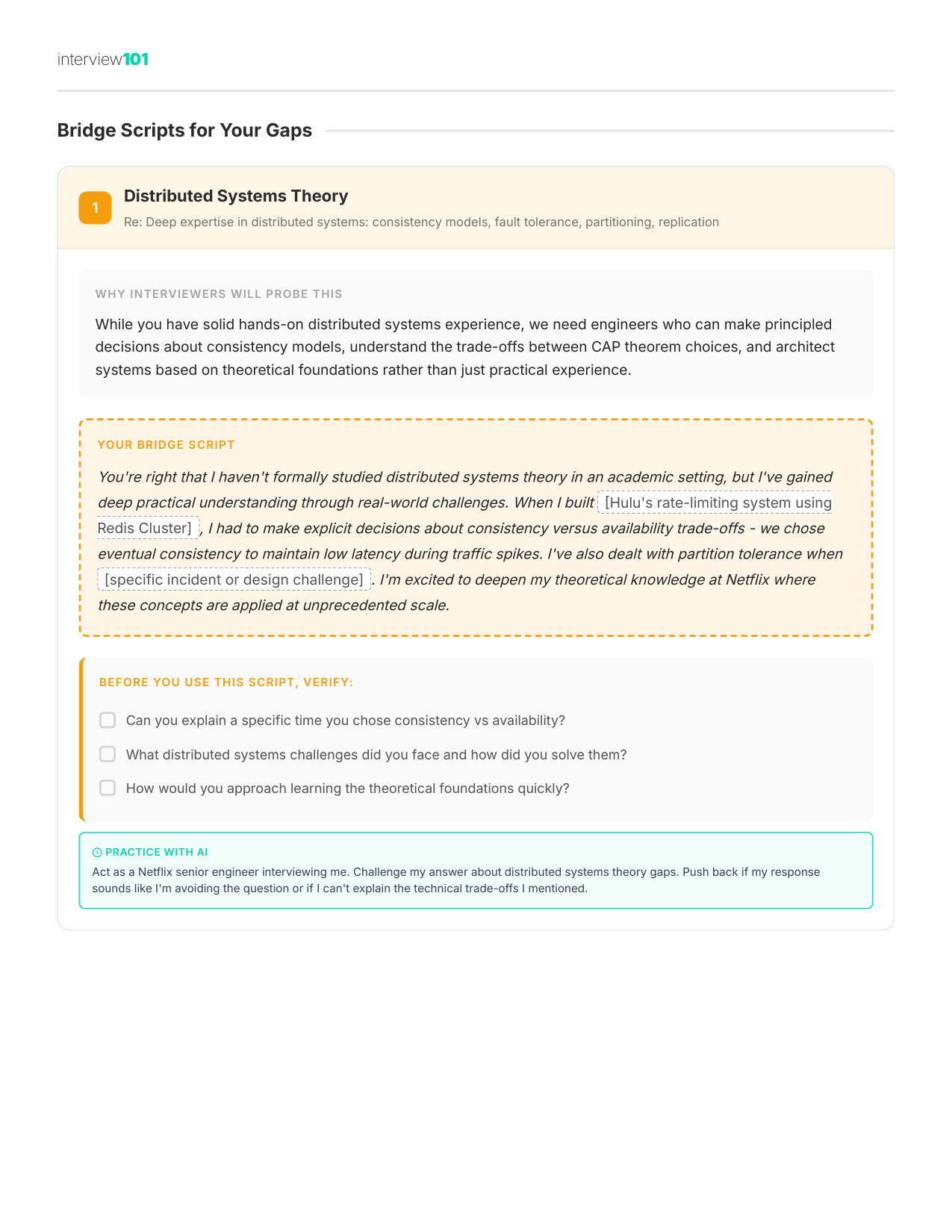
8 / 11Scripts for Awkward Questions
Zoom
9 / 11Your Gap Script
Zoom
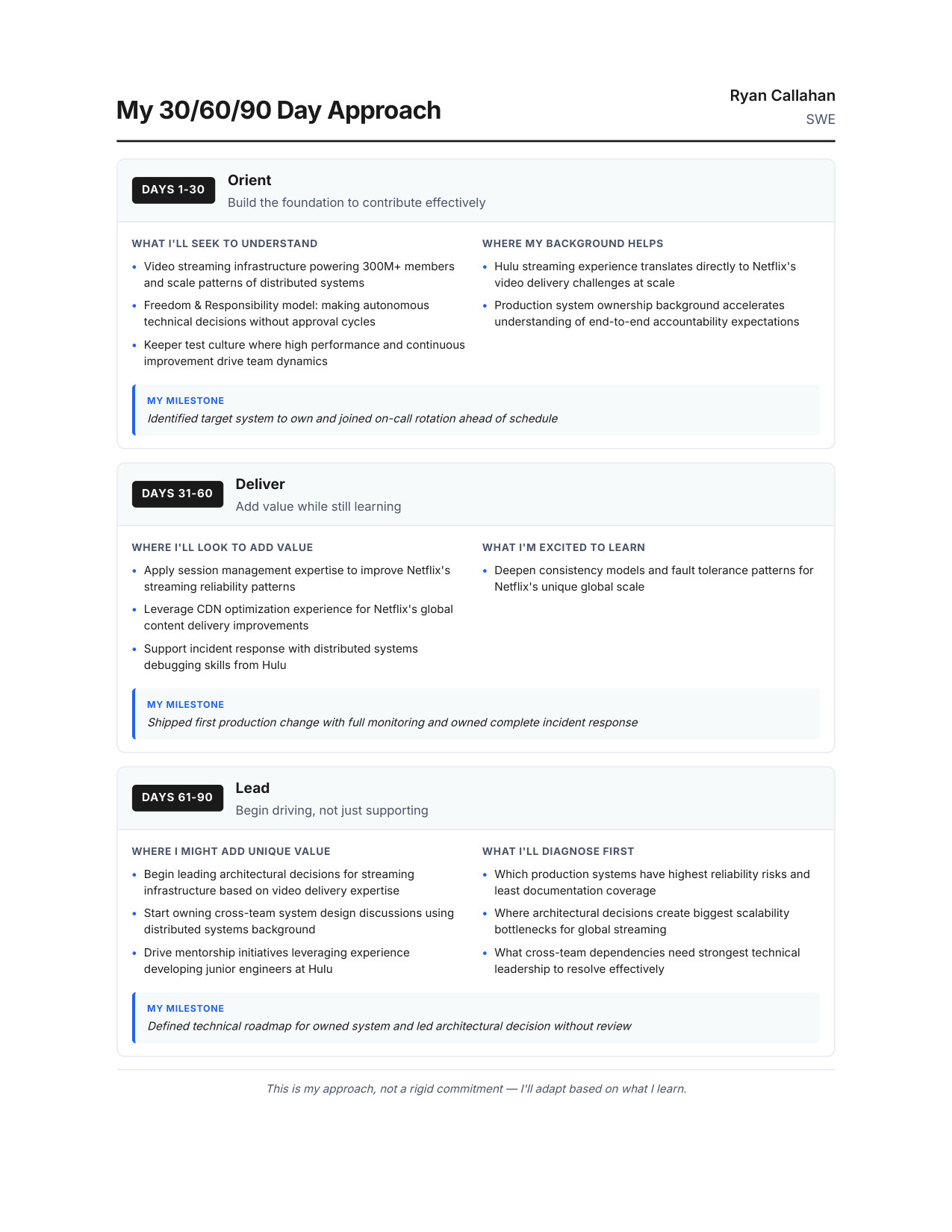
10 / 1130/60/90 Day Plan
Zoom
11 / 11Interview Day Cheat Sheet
Zoom
Download the Full Sample Report — Free
See exactly what you're buying before you commit — 50+ pages, no email required
🔒 30-day money-back guarantee — no questions asked
FAQ
Common Questions About the Netflix Machine Learning Engineer Interview
The Netflix Machine Learning Engineer interview process typically takes 3-5 weeks from application to offer. This timeline includes the initial screen, take-home modeling quiz (which you'll have 3-5 days to complete), coding interview, and final onsite loop.
Netflix has 4 interview stages for Machine Learning Engineer roles: Initial Screen (45-60 minutes), Take-Home Modeling Quiz (3-5 days to complete), Coding Interview (45-60 minutes), and Onsite Loop (4-5 hours). The interview structure may vary by team and level, so confirm the specific format with your recruiter.
ML system design is the primary evaluation signal and highest-weighted component of Netflix's Machine Learning Engineer interview. Focus heavily on designing scalable recommendation systems, personalization algorithms, and ML infrastructure that can handle Netflix's scale and business requirements.
The Netflix Machine Learning Engineer interview is challenging, with ML system design being the primary difficulty rather than traditional algorithm problems. You'll need strong business judgment for the take-home modeling quiz, solid Python ML implementation skills, and deep understanding of recommendation systems and personalization at scale.
Yes, Netflix Culture Principles questions appear in every interview round alongside technical questions, rather than in dedicated behavioral sessions. Netflix evaluates Freedom and Responsibility and their keeper-test culture throughout the process, with directors frequently participating in onsite loops.
Netflix coding focuses on Python ML implementation rather than traditional algorithm practice. Expect to implement recommendation metrics (precision@k, NDCG), similarity functions (cosine, Jaccard), collaborative filtering algorithms, or data pipeline logic with Spark/PySpark. Some roles include GenAI coding like embeddings and RAG components, and you'll write code without IDE support.
This page shows you what the Netflix Machine Learning Engineer interview looks like in general. Your personalized report shows you how to prepare specifically — using your resume, a real job description, and Netflix's actual evaluation criteria.
This page shows every Netflix MLE candidate the same thing. Your report is built around you — your resume, your gaps, your most likely questions.
What's inside: your fit score broken down by skill, experience, and culture; your top 3 risk areas by name; the 12 questions most likely for your specific background with full answer decodes; your experiences mapped to the Netflix Culture Principles you'll face; scripts for when they probe your weakest spots; sharp questions to ask your interviewers; and a one-page cheat sheet to review before you walk in. 55 pages. Delivered within 24 hours.
Within 24 hours. Your report is reviewed and delivered to your inbox within 24 hours of payment. Most orders arrive significantly faster. You'll receive an email with your personalized PDF as soon as it's ready.
30-day money-back guarantee, no questions asked. If your report doesn't help you feel more prepared, email us and we'll refund in full.