Streaming Pipeline Ownership at 2 Trillion Events/Day — Data Freshness is a Business SLA
4–8
Weeks Timeline
Application to offer
$210–520K
Total Compensation
Base + Stock + Bonus
Questions sourced from reported interviews
Every claim traced to a verified source
Updated quarterly — data stays current
2,600+ reported interviews analyzed
Self-Assessment
Is This Role Right for You?
See what Netflix looks for in Data Engineer candidates and check how you measure up.
What strong candidates bring to the role:
Strong candidates bring hands-on experience owning data pipelines in production including on-call responsibility, data quality incident management, and end-to-end ownership from design through monitoring through permanent fixes.
Strong candidates bring experience with real-time data processing at scale using technologies like Kafka, Flink, or Spark Streaming, with specific knowledge of handling late data, deduplication, and maintaining data freshness SLAs.
Strong candidates bring sophisticated SQL skills including window functions for deduplication and sessionization, complex CTEs, and experience designing analytics data models that handle duplicate events and late-arriving data correctly.
Strong candidates bring experience making significant data architecture decisions independently including schema design, storage format selection, and pipeline pattern choices without requiring committee approval or extensive review processes.
What Netflix Looks For
Netflix rewards data engineers who embrace autonomous ownership of production systems — from initial design through on-call responsibility, treating pipeline reliability as a business obligation rather than just a technical requirement.
Free — Takes 60 seconds
See your personal gap risk profile
Upload your resume and your target job description. Get your fit score, your top 3 risks, and exactly what to prepare first — before you spend another hour prepping the wrong things.
Netflix Data Engineers own streaming pipelines that process member viewing events, content performance metrics, and A/B testing data at unprecedented scale. Unlike other companies where data freshness is an operational metric, at Netflix it's a business-critical SLA — recommendation quality depends directly on how quickly member behavior flows through your pipelines to the personalization models.
What's Different at Netflix
Netflix rewards data engineers who embrace autonomous ownership of production systems — from initial design through on-call responsibility, treating pipeline reliability as a business obligation rather than just a technical requirement.
Streaming Architecture Expertise
You'll design real-time data pipelines using Netflix's specific stack: Kafka for ingestion, Flink via Keystone for stream processing, and Iceberg with WAP pattern for safe publishing. Netflix tests whether you understand how their trillion-event-per-day scale creates unique architectural constraints around deduplication, late data handling, and pipeline monitoring.
Data Freshness as SLA
Netflix evaluates whether you frame pipeline latency in business terms rather than purely technical metrics. Strong candidates explain how a 4-hour delay in member viewing events degrades recommendation quality, demonstrating that you understand the connection between data infrastructure performance and product outcomes.
Autonomous Pipeline Ownership
Freedom and Responsibility means Netflix Data Engineers make architectural decisions independently and own their systems in production. You'll be assessed on your experience owning data quality incidents end-to-end: detection, diagnosis, mitigation, and permanent fixes without committee oversight or handoffs to other teams.
Your Report Adds
Netflix's Netflix Culture Principles are mapped directly to the bullet points on your resume. You'll see exactly which ones you can claim with evidence — and which ones are gaps to address before the interview.
The Netflix Data Engineer interview timeline varies by team — confirm the specifics with your recruiter.
Important: Netflix DE interview loops vary by team — verify your specific structure with your recruiter. The consistent elements: SQL at medium-hard difficulty with member event deduplication and sessionization, Python or Scala for Spark/pipeline logic, streaming pipeline system design at Netflix-specific scale, data modeling for analytics workloads, and behavioral culture fit. A take-home project (working data pipeline or system design document) is possible for some teams. Freedom and Responsibility is evaluated throughout — not just in a dedicated behavioral round.
1
SQL & Data Modeling
45-60 min
Medium-hard SQL problems using Spark SQL or Trino syntax, focusing on member event deduplication, sessionization with window functions, and analytics queries that handle duplicate events correctly.
Evaluates
Advanced SQL proficiencyunderstanding of data deduplication at scaleanalytics modeling
2
Streaming Pipeline Design
60-90 min
System design focused on Netflix's streaming data architecture using Kafka, Keystone/Flink, Iceberg, and WAP pattern. Scenarios include real-time member event pipelines with data freshness SLAs.
PySpark or Scala implementation of pipeline logic including DataFrame transformations, partition optimization, late data handling, and scale-appropriate deduplication strategies.
Freedom and Responsibility evaluation through stories of autonomous pipeline ownership, data quality incident management, and architectural decision-making without committee oversight.
Your report includes a stage-by-stage prep checklist built around your background — what to emphasize in each round, based on the specific gaps between your resume and this role.
At Netflix, every Data Engineer candidate is evaluated against their Netflix Culture Principles. Expand each one below to see what interviewers are actually looking for.
Technical EvaluationAssessed alongside Netflix Culture Principles in every round
Production Pipeline Ownership Experience
Strong candidates bring hands-on experience owning data pipelines in production including on-call responsibility, data quality incident management, and end-to-end ownership from design through monitoring through permanent fixes.
Streaming Data Architecture Background
Strong candidates bring experience with real-time data processing at scale using technologies like Kafka, Flink, or Spark Streaming, with specific knowledge of handling late data, deduplication, and maintaining data freshness SLAs.
Advanced SQL and Analytics Modeling
Strong candidates bring sophisticated SQL skills including window functions for deduplication and sessionization, complex CTEs, and experience designing analytics data models that handle duplicate events and late-arriving data correctly.
Autonomous Technical Decision Making
Strong candidates bring experience making significant data architecture decisions independently including schema design, storage format selection, and pipeline pattern choices without requiring committee approval or extensive review processes.
All Netflix Culture Principles — click any to see how to demonstrate it
Netflix expects data engineers to be production owners, not just builders. This means you're responsible for the operational health of your pipelines 24/7, from initial data ingestion through final consumption. The company culture emphasizes that building a pipeline is only 20% of the work — the other 80% is ensuring it runs reliably in production with proper monitoring, alerting, and incident response capabilities.
How to Demonstrate: Walk through a specific pipeline where you designed the monitoring strategy, not just the data flow. Describe the SLIs you chose, why you set alert thresholds at specific percentiles, and how you balanced alert noise versus detection speed. Share details about being paged at 2 AM for a data quality issue and how you triaged it using your own runbook. Mention specific on-call experiences where your monitoring caught upstream dependencies failing before they impacted downstream consumers.
At Netflix, data freshness isn't just a technical SLA — it directly impacts member experience and business metrics. Late data means recommendation models are personalizing on stale behavior patterns, which reduces click-through rates and member engagement. Netflix DEs are expected to understand this business context and make engineering trade-offs accordingly, sometimes choosing more expensive real-time solutions over batch processing when freshness matters for product outcomes.
How to Demonstrate: Quantify the business impact of latency in your examples — don't just say 'data was late.' Explain how a 2-hour delay in user engagement events meant recommendation models were using yesterday's viewing patterns, which reduced recommendation accuracy by X%. Describe trade-offs you made between cost and freshness, like choosing streaming over batch processing when real-time personalization was critical. Show you can translate technical metrics like P95 latency into business language that product managers understand.
Netflix operates at massive scale where duplicate events and retry scenarios are inevitable, not edge cases. The company requires pipelines that maintain data correctness even when upstream services double-log events, when late-arriving data appears hours after processing, or when retry storms create thousands of duplicate messages. This goes beyond basic at-least-once delivery to ensuring business logic correctness under real production failure modes.
How to Demonstrate: Describe specific deduplication strategies you've implemented, not just theoretical approaches. Explain how you used natural keys or event_id fields to detect duplicates across partition boundaries. Detail your experience with techniques like partition-delete-and-rewrite for handling late data corrections. Share examples of designing idempotent transforms where re-running the same input produces identical output. Discuss how you validated deduplication logic during retry storms or when upstream systems sent duplicate events hours apart.
Netflix gives individual contributors significant architectural autonomy, expecting them to make complex technical decisions without extensive committee oversight. DEs are trusted to choose storage formats, design schemas, select pipeline patterns, and architect solutions based on their domain expertise. This freedom comes with the responsibility to research thoroughly, consider trade-offs, and own the consequences of architectural choices.
How to Demonstrate: Share specific examples where you independently chose between competing architectural approaches — like selecting Parquet versus Avro for a specific use case based on compression ratios and query patterns you measured. Describe schema evolution decisions you made autonomously, explaining the backward compatibility strategy you designed. Detail storage partitioning strategies you implemented based on query access patterns you analyzed. Avoid examples that required extensive approval processes — Netflix wants to see you took ownership of complex technical decisions.
Netflix evaluates DE candidates on their ability to independently handle production data incidents from detection through permanent resolution. This means identifying anomalies in your monitoring, conducting root cause analysis without escalation, implementing immediate workarounds to restore service, and designing long-term fixes to prevent recurrence. The company expects you to operate as the technical authority during incidents in your data domain.
How to Demonstrate: Walk through a complete incident timeline where you personally drove resolution. Start with how your monitoring detected the anomaly — specific metrics that alerted you. Explain your diagnostic process: the queries you ran, logs you analyzed, and hypotheses you tested to identify root cause. Detail both your immediate mitigation (like routing traffic around a corrupted partition) and permanent fix (like adding schema validation). Emphasize decisions you made independently during the incident, not collaborative debugging sessions.
Netflix expects DE candidates to demonstrate genuine interest in the company by understanding their published technical challenges and solutions. This goes beyond generic streaming knowledge to specific familiarity with Netflix's scale (trillion events per day), their architectural patterns (WAP for safe publishing), and their technology choices (Iceberg for lakehouse). Understanding these published details shows you've invested time learning about Netflix's specific data engineering environment.
How to Demonstrate: Reference specific Netflix blog posts or conference talks about their data architecture, and connect them to your own experience. Discuss how you've solved similar challenges to their trillion-event-per-day Keystone platform, or how you've implemented Write-Audit-Publish patterns for data quality. Explain why Iceberg's features (like schema evolution and time travel) matter for Netflix's use cases specifically. Connect technical infrastructure to business outcomes — how pipeline reliability affects recommendation quality and member engagement metrics.
Your Report Adds
Your report scores you against each of these criteria using your resume and the job description — you get a ranked list of where you're strong vs. where you need to build a case before your interview.
Showing 12 questions drawn from 2,600+ reported interviews — ranked by frequency for Netflix Data Engineer candidates.
Your report selects the 12 questions you're most likely to face based on your resume.
Get yours →
Sql3 questions
"We have a member_viewing_events table with columns (member_id, content_id, event_timestamp, session_id, event_id, watch_duration_seconds). Due to network retries, the same event_id can appear multiple times. Write a SQL query to calculate daily active streamers (members who watched at least 30 seconds in a day) ensuring no double-counting from duplicate events. Use window functions for deduplication and handle the case where the same member might have multiple valid sessions per day."
Sql
· Reported 31 times
What they're really asking
This tests your understanding that deduplication must happen BEFORE aggregation, not after. The interviewer wants to see you use ROW_NUMBER() OVER (PARTITION BY event_id ORDER BY ingestion_time) to dedupe first, then aggregate. They're also checking if you understand that a member can legitimately appear multiple times per day across different sessions.
What Great Looks Like
Demonstrates event_id-based deduplication using window functions, correctly handles the 30-second threshold after deduplication, and shows awareness that members can have multiple valid sessions per day requiring session-level aggregation before member-level counting.
What Bad Looks Like
Attempts to dedupe after aggregation using DISTINCT member_id, ignores the event_id duplication problem entirely, or doesn't account for the business logic that members can legitimately stream multiple times per day.
"Given a member_playback_events table, write a query to identify viewing sessions using sessionization logic. A new session starts if there's a gap of more than 30 minutes between consecutive events for the same member. Calculate session_duration for each session and rank sessions by duration within each day. Handle edge cases where members have single-event sessions."
Sql
· Reported 28 times
What they're really asking
This evaluates your ability to use LAG() window functions for time-based sessionization and handle edge cases in real streaming data. The interviewer wants to see you identify session boundaries correctly and understand that single events constitute valid sessions with zero duration.
What Great Looks Like
Uses LAG() to compare timestamps, correctly identifies session boundaries with conditional logic for 30-minute gaps, handles single-event sessions as duration zero, and uses appropriate partitioning for ranking sessions within days.
What Bad Looks Like
Attempts sessionization with simple GROUP BY instead of window functions, doesn't handle single-event sessions, or incorrectly calculates session duration by not accounting for session boundary detection.
"You're analyzing member engagement cohorts. Given tables member_registrations (member_id, registration_date) and viewing_events (member_id, event_date, content_type), write a query to calculate weekly cohort retention. For each registration week cohort, show what percentage of members were active (had any viewing event) in weeks 1, 2, 4, and 8 after registration. Use RANK() for cohort assignment and handle members who registered on different days within the same week."
Sql
· Reported 25 times
What they're really asking
This tests your ability to build cohort analysis with proper date arithmetic and percentage calculations across multiple time windows. The interviewer wants to see you correctly handle week-based grouping and understand that cohort analysis requires careful handling of the time dimension.
"Tell me about a time when you owned a data pipeline end-to-end in production. Walk me through the entire lifecycle from initial design through ongoing operational responsibility. What did your monitoring and alerting look like, and how did you handle being on-call for your pipeline?"
BehavioralPipeline ownership end-to-end
· Reported 35 times
What they're really asking
This evaluates whether you understand that at Netflix, building a pipeline is just the beginning - ownership means you're responsible for its operational health forever. They want to see evidence of production alerting design, runbook creation, and actual on-call experience, not just development work.
"Describe a data quality incident you owned from detection through resolution. How did you identify the problem, what was your immediate mitigation strategy, and what permanent changes did you implement to prevent recurrence? Focus on your individual contribution and decision-making."
BehavioralAutonomous incident ownership
· Reported 33 times
What they're really asking
This probes for the 'keeper test' standard at Netflix - can you own complex production issues independently? They want to see autonomous technical decision-making under pressure, not collaborative problem-solving or escalation to senior engineers.
"Give me an example of a significant data architecture decision you made autonomously - choosing storage formats, designing schema patterns, or selecting processing frameworks. What factors influenced your decision and how did you evaluate trade-offs without committee consensus?"
BehavioralFreedom and Responsibility in architecture
· Reported 29 times
What they're really asking
This tests whether you can operate with Netflix-level autonomy in technical decision-making. They want to see you made consequential architecture decisions independently, not just implemented decisions made by others or followed team consensus processes.
"Walk me through a time when pipeline latency directly impacted business outcomes. How did you frame the problem for stakeholders, what was your solution approach, and how did you measure success? Be specific about the business connection."
BehavioralData freshness as a business obligation
· Reported 27 times
What they're really asking
This evaluates whether you understand how data infrastructure connects to product outcomes at Netflix scale. They want to see you can translate technical pipeline metrics into business impact language and prioritize accordingly.
"You have a PySpark DataFrame containing member viewing events that may include late-arriving data and duplicate events. Write PySpark code to implement a deduplication strategy that handles both duplicate event_ids and late arrivals. Your solution should be idempotent and optimized for large-scale processing. Consider partitioning strategy and memory optimization."
Coding
· Reported 24 times
What they're really asking
This tests your ability to handle real Netflix production scenarios where deduplication must work at trillion-event scale. The interviewer wants to see you consider partition-based deduplication strategies and understand that simple dropDuplicates() won't scale to Netflix's data volumes.
"Write PySpark code to implement late data handling for a streaming pipeline that processes member engagement events. Events can arrive up to 24 hours late. Your solution should update existing aggregations correctly and maintain exactly-once semantics. Include error handling for corrupt or malformed events."
Coding
· Reported 22 times
What they're really asking
This evaluates your understanding of exactly-once processing guarantees in streaming systems and how to handle late data without double-counting. The interviewer wants to see you understand watermarking, state management, and graceful degradation for bad data.
"Design a real-time content performance analytics pipeline for Netflix. The system needs to process CDN log events (5M events/second globally) to calculate content popularity metrics with 10-minute freshness SLA for content recommendation systems. Include deduplication strategy, data freshness guarantees, and how you'd handle traffic spikes during major releases."
System Design
· Reported 26 times
What they're really asking
This tests your ability to design for Netflix's actual scale and business requirements. The interviewer wants to see you understand that content performance data directly feeds recommendation algorithms, so latency and correctness are business-critical, not just engineering nice-to-haves.
"Design a backfill system for Netflix's Keystone platform when an upstream data source correction requires reprocessing 30 days of member viewing events (50TB of data). The backfill must maintain data freshness for ongoing real-time processing while recomputing historical aggregations. Explain your WAP (Write-Audit-Publish) strategy."
System Design
· Reported 21 times
What they're really asking
This evaluates your understanding of Netflix's actual Iceberg-based architecture and the WAP pattern for safe data publishing. The interviewer wants to see you can design systems that handle massive historical reprocessing without disrupting production workloads.
"Design data infrastructure to support Netflix's personalization A/B testing at scale. Handle experiment assignment events (1M/sec), ensure assignment consistency across sessions, and provide data scientists with experiment result queries under 30-minute latency. Include your deduplication and assignment integrity strategy."
System Design
· Reported 19 times
What they're really asking
This tests whether you understand that A/B testing infrastructure is mission-critical at Netflix and requires specialized handling for assignment consistency and statistical validity. The interviewer wants to see you solve for assignment deduplication and temporal consistency.
These are the questions Netflix Data Engineer candidates report facing most. Your report takes it further — 12 questions matched to your resume, with what great looks like, red flags to avoid, and which of your experiences to use for each one.
Your report selects 12 questions ranked by likelihood given your specific profile — and for each one, identifies the story from your resume you should tell and the angle most likely to land with Netflix's interviewers.
How to Prepare for the Netflix Data Engineer Interview
A structured prep framework based on how Netflix actually evaluates Data Engineer candidates. Work through these focus areas in order — how much time you spend on each depends on your timeline and starting point.
Phase 1: Understand the Game
Before you prep anything, understand how Netflix actually evaluates you
Learn how Netflix's Netflix Culture Principles work in practice — not as corporate values, but as the actual rubric interviewers use to score you
Understand that two evaluation tracks run simultaneously in every interview: technical depth and Netflix Culture Principles. Most candidates over-index on one
Learn what the Streaming Pipeline Ownership at 2 Trillion Events/Day — Data Freshness is a Business SLA process means and how it changes the interview dynamic
Build the technical competency Netflix expects for this role
Master advanced SQL with Spark SQL/Trino syntax including window functions for deduplication (ROW_NUMBER, RANK), sessionization patterns (LAG/LEAD), and CTEs for complex analytics queries
Practice PySpark DataFrame transformations focusing on partition optimization, handling late-arriving data, and implementing deduplication strategies at scale
Study Netflix's published data stack: Keystone (Kafka+Flink), WAP pattern (Write-Audit-Publish), Iceberg table format, and Maestro workflow scheduling
Design streaming pipeline architectures that treat data freshness as a business SLA, not just a technical metric, with concrete latency requirements
Prepare system design scenarios for real-time member event processing, A/B testing data infrastructure, and content analytics pipelines at Netflix scale
Practice explaining your approach while you solve, not after. Interviewers score your process, not just the answer
Phase 3: Netflix Culture Principles Preparation
Not a separate "behavioral round" — woven into every interview
Netflix Culture Principles evaluation is woven throughout technical discussions, with interviewers probing for autonomous ownership examples and business-aware thinking during pipeline design and SQL problem-solving sessions.
Build 2–3 strong experiences per Netflix Culture Principles principle — not one per principle
Each experience needs a measurable outcome. Quantify impact wherever possible — business results, scale, adoption, or efficiency gains with real numbers
Your experiences must be real and traceable to your actual background. Interviewers probe deeply — vague or fabricated stories fall apart under follow-up questions
Focus first on the most frequently tested principles for this role: Pipeline ownership end-to-end — show you own data pipelines from ingestion through transformation through storage through monitoring through on-call; Netflix DEs who hand off operational responsibility after building a pipeline are not meeting the bar; show you designed the alerts, wrote the runbook, and were on-call for what you built, Data freshness as a business obligation — frame pipeline latency in business terms: a pipeline that delivers member viewing events 4 hours late degrades recommendation quality because the model is personalizing on yesterday's behavior; this framing demonstrates that you understand how data infrastructure connects to product outcomes at Netflix, Deduplication correctness and idempotency — show you have designed pipelines where correctness under failure is a first-class requirement; double-logging, late events, and retry storms are real Netflix production scenarios; demonstrate you have solved deduplication at scale using event_id keys, partition-delete+rewrite, and idempotent sinks
Phase 4: Integration
The phase most candidates skip — and most regret
Practice a 60-minute streaming pipeline design session followed immediately by a Freedom and Responsibility behavioral question about owning a data quality incident, simulating how Netflix integrates technical depth with culture evaluation.
Practice out loud, timed, from start to finish. Silent practice does not prepare you for the pressure of speaking under scrutiny
Identify your weakest Netflix Culture Principles area and your weakest technical area. Spend disproportionate final-week time there — interviewers will probe your gaps
Do a full dry-run 2–3 days before your interview. Not the day before — you need time to course-correct
Netflix-Specific Tip
Netflix rewards data engineers who embrace autonomous ownership of production systems — from initial design through on-call responsibility, treating pipeline reliability as a business obligation rather than just a technical requirement.
Watch Out For This
“A client release bug causes double-logging of the same member viewing event (same member_id, session_id, event_name, event_ts) for 2 hours before being fixed. Your downstream daily active streamers dashboard and personalization feature pipeline cannot tolerate inflated event counts. Walk me through how you handle this end-to-end — detection, immediate mitigation, root cause fix, and what you change permanently.”
This is Netflix's canonical DE production scenario — double-logging is a confirmed real incident pattern at Netflix and event deduplication correctness is a primary DE competency. The question tests four simultaneous dimensions: detection sophistication (can you catch this in monitoring before a PM notices?), deduplication strategy at scale (ROW_NUMBER on event_id, partition-delete + rewrite, or Flink stateful dedup — each with different trade-offs), business impact awareness (connecting inflated event counts to degraded recommendation quality and invalid A/B test results), and permanent fix ownership (what monitoring, schema change, or pipeline pattern prevents this class of incident recurrence). Candidates who only describe the deduplication SQL without addressing detection, business impact, and permanent fix reveal they do not own pipelines in production at Netflix's standard.
Your report includes the full answer framework for this question and Netflix's other curveball questions — mapped to your specific background.
This plan works for any Netflix Data Engineer candidate.
Your report makes it specific to you — the exact gaps in your background, the exact questions your resume makes likely, and a clear picture of exactly what to focus on given your specific risks.
Your report includes 8 stories pre-drafted from your resume, each mapped to a specific Netflix Netflix Culture Principles and competency. You practice answers — you don't write them from scratch the week before your interview.
You've worked too hard for your resume to fail the Netflix DE interview. Walk in knowing your 3 biggest red flags — and exactly what to say when they surface.
Not hoping you prepared the right things. Knowing.
Your report starts with your resume, scores you against this exact role, and tells you which Netflix Culture Principles you can prove with evidence — and which ones Netflix will probe. Then it shows you exactly what to do about the gaps before they find them. Your STAR stories are pre-drafted from your own experience. Your gap scripts are written for your specific vulnerabilities. Nothing generic.
This Page — Free Guide
✓ What Netflix looks for in any DE
✓ Most likely questions from reported interviews
✓ General prep framework
🔒 How your background measures up
🔒 Your 12 specific questions
🔒 Scripts for your gaps
→
Your Report — Personalized
✓ Your 3 biggest red flags — identified by name
✓ Exact bridge scripts for each gap
✓ Your STAR stories pre-drafted from your resume
✓ Question types most likely for your background
✓ Your experiences mapped to Netflix Culture Principles
✓ Your fit score against this exact role
What's Inside Your 55-Page Report
1
Orientation
The unspoken bar Netflix sets — what most candidates miss before they even walk in
2
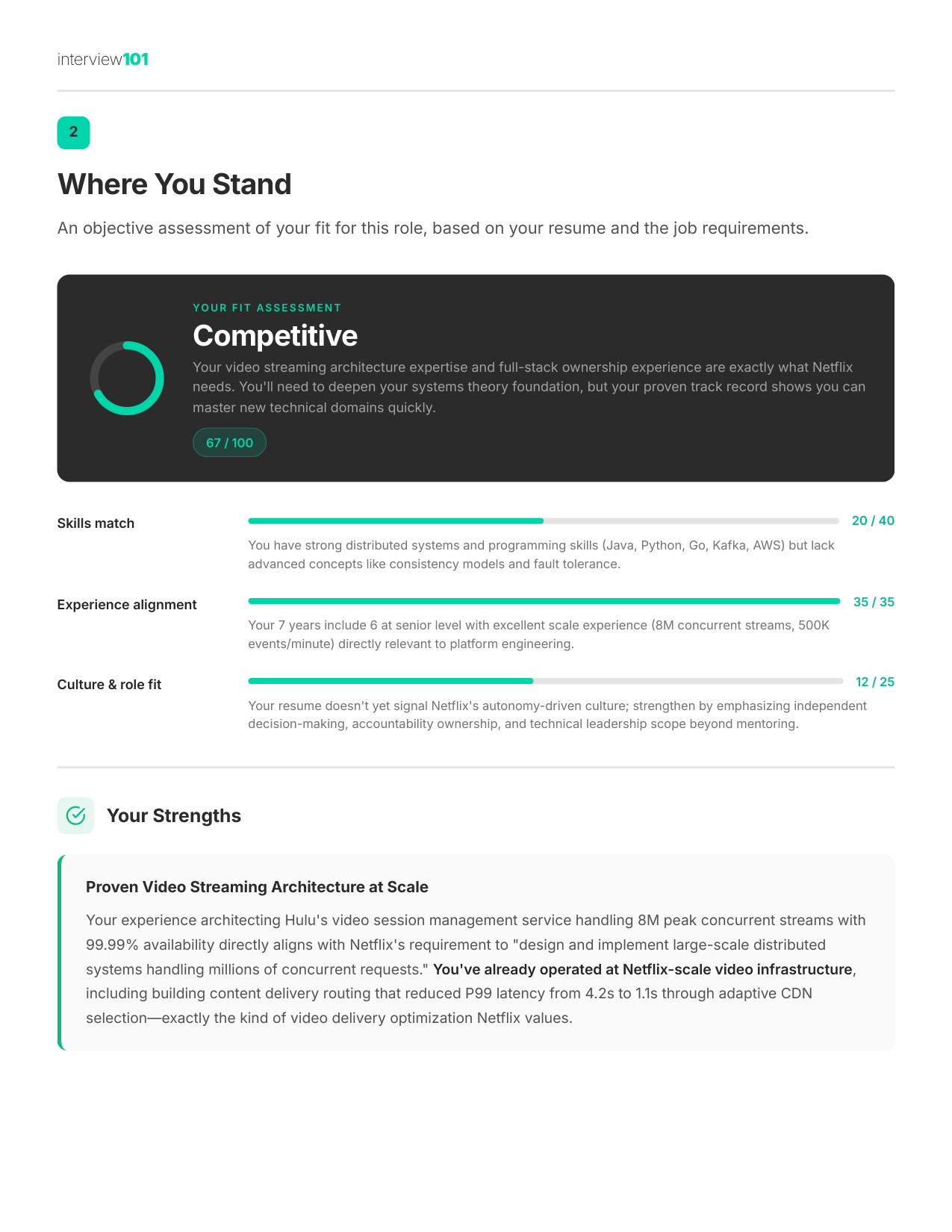
Where You Stand
Your fit score by skill, experience, and culture fit — know your strengths before they probe your gaps
3
What They Actually Want
The real criteria interviewers score you on — beyond what the job description says
4
Your Story
Your resume reframed for Netflix's lens — how to position your background so it lands
5
Experience That Wins
Your specific experiences mapped to the Netflix Culture Principles you'll face — walk in knowing which examples to use
6
Questions You Will Face
The question types most likely given your background — with what a strong answer looks like for someone in your position
7
Scripts for Awkward Questions
Exact words for when they probe your weakest areas — so you do not freeze when it matters most
8
Questions to Ask Them
Sharp questions that signal preparation and seniority — and make interviewers remember you
9
30/60/90 Day Plan
Show Netflix you're already thinking like an employee — demonstrates ownership from day one
10
Interview Day Cheat Sheet
One page. Everything you need. Review 5 minutes before you walk in — and walk in ready.
How It Works
1
Upload your resume + target JD
The job description you're actually applying to — not a generic one
2
We analyze your fit
Your background is scored against the Netflix DE blueprint — gaps, strengths, likely questions
3
Your report arrives within 24 hours
55-page personalized PDF delivered to your inbox — ready to work through before your interview
See Inside the Report
Real pages from a Netflix Software Engineer report
Your DE report follows the same structure — built entirely around your background and this role.
1 / 11Your Interview Prep Starts Here
Zoom
2 / 11Where You Stand
Zoom
3 / 11What They Actually Want
Zoom
4 / 11Your 2-Minute Pitch
Zoom
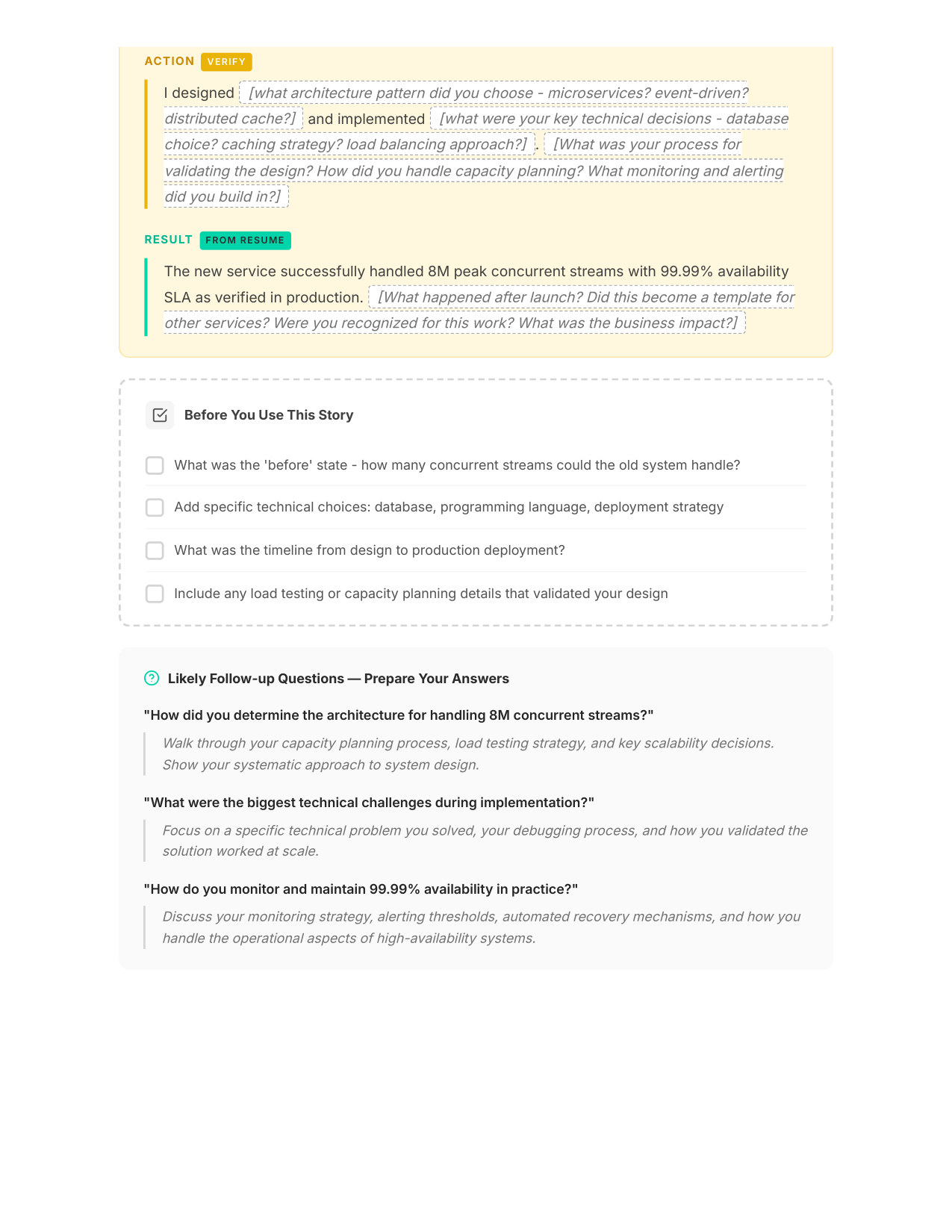
5 / 11Your STAR Story (Page 1)
Zoom
6 / 11Your STAR Story (Page 2)
Zoom
7 / 11Questions You'll Face
Zoom
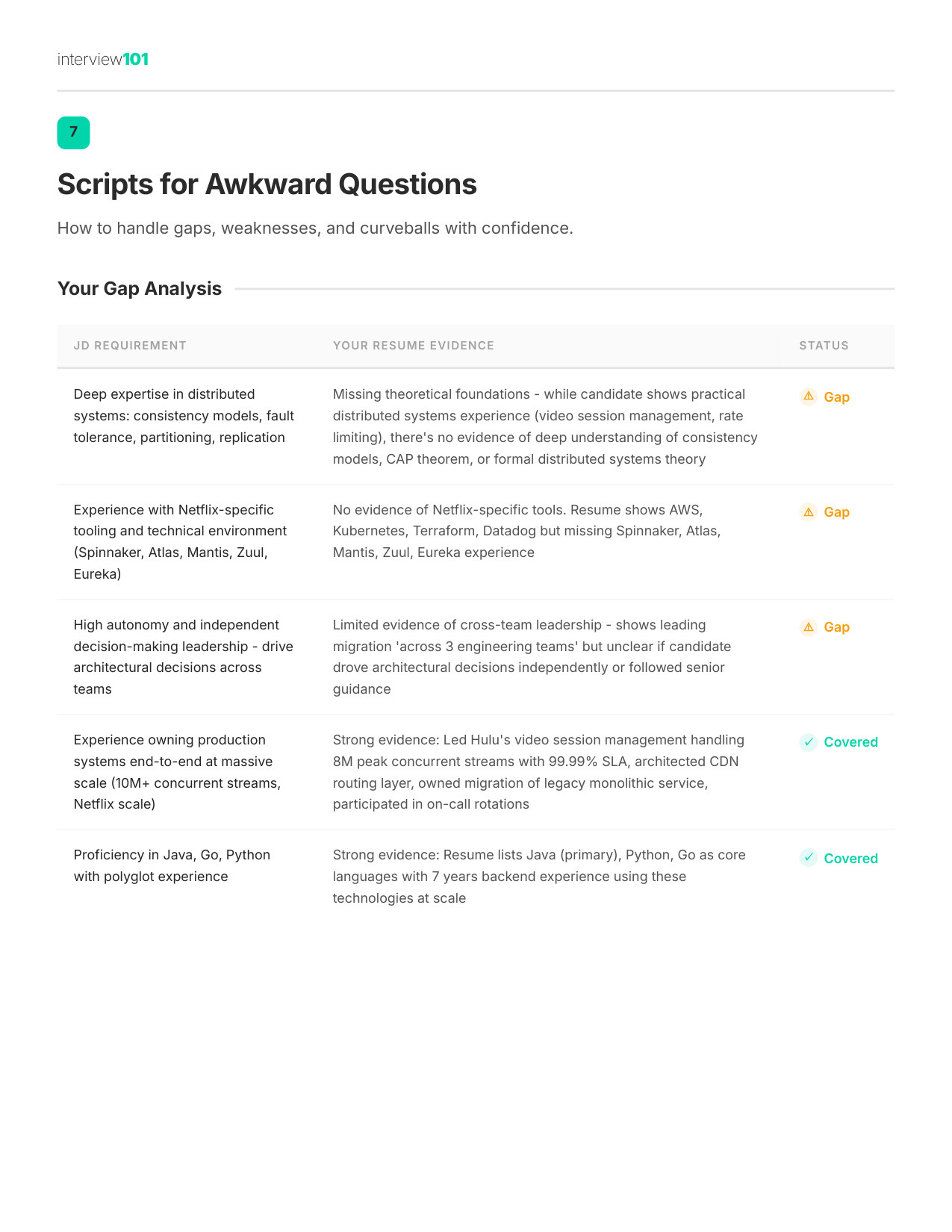
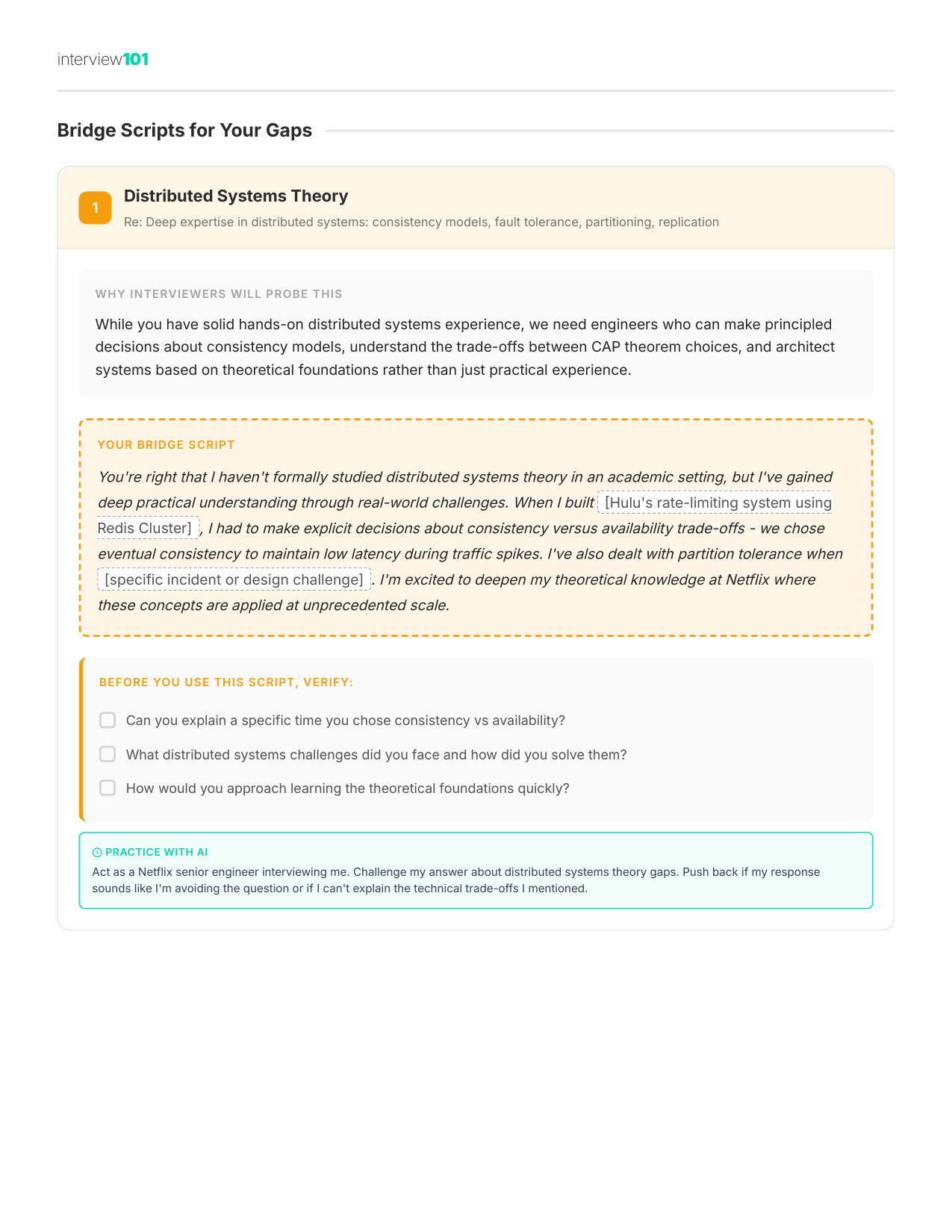
8 / 11Scripts for Awkward Questions
Zoom
9 / 11Your Gap Script
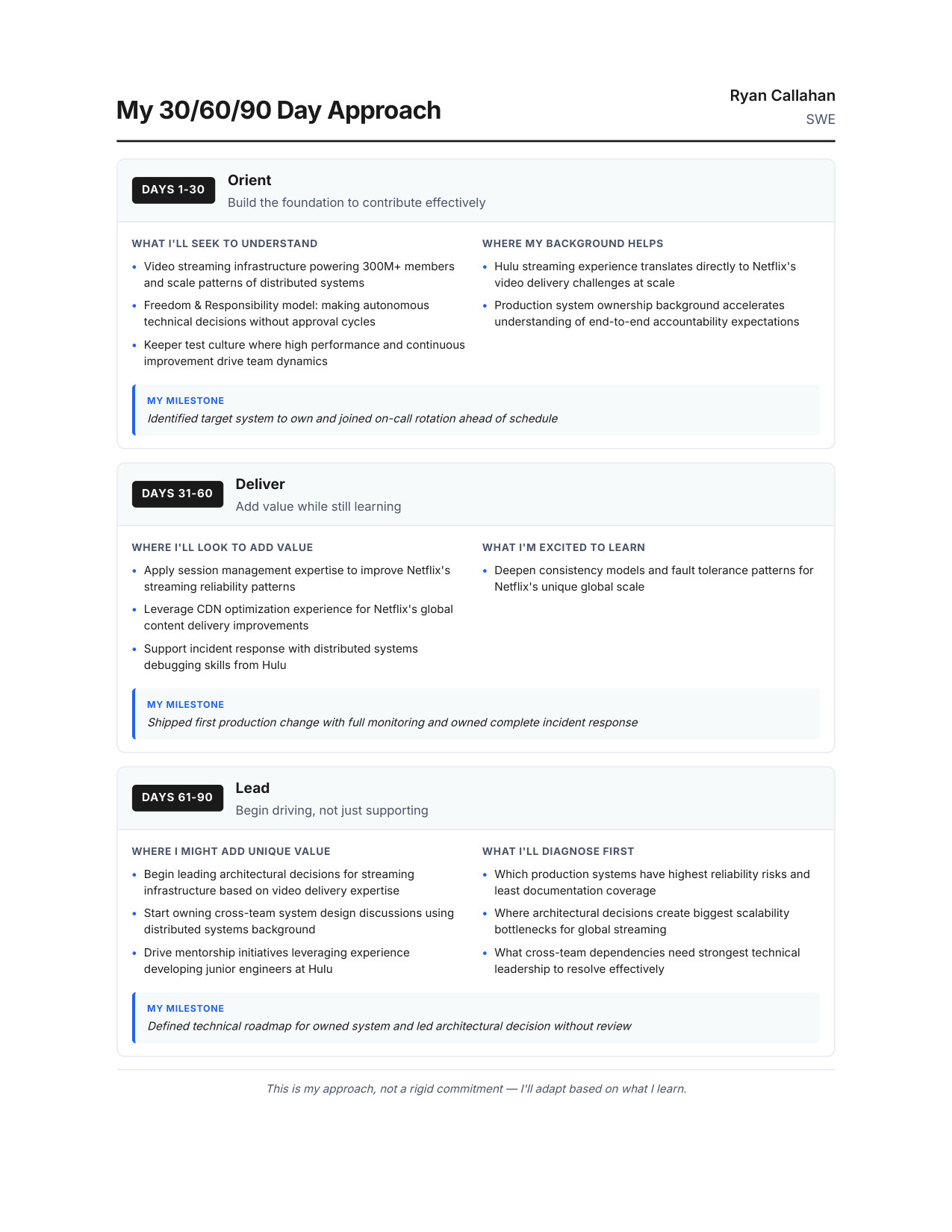
Zoom
10 / 1130/60/90 Day Plan
Zoom
11 / 11Interview Day Cheat Sheet
Zoom
Download the Full Sample Report — Free
See exactly what you're buying before you commit — 50+ pages, no email required
🔒 30-day money-back guarantee — no questions asked
FAQ
Common Questions About the Netflix Data Engineer Interview
The Netflix Data Engineer interview process typically takes 3-5 weeks from application to offer. This timeline can vary depending on scheduling availability and the specific team you're interviewing with, so it's worth confirming the expected timeline with your recruiter during the initial conversation.
Netflix Data Engineer interviews consist of 4 rounds: SQL & Data Modeling (45-60 min), Streaming Pipeline Design (60-90 min), Pipeline Coding (45-60 min), and Culture & Ownership (45-60 min). Each round combines technical questions with Netflix Culture Principles assessment, and the specific structure may vary by team, so verify details with your recruiter.
Focus on Netflix's tech stack and scale-specific challenges: medium-hard SQL with member event deduplication and sessionization using window functions, PySpark for large-scale data pipeline transformations, and streaming system design at Netflix's massive scale. Equally important is understanding Netflix Culture Principles like Freedom and Responsibility, as these are evaluated in every round alongside technical skills.
Netflix Data Engineer interviews are challenging and focus on real-world data problems at Netflix scale. You'll face medium-hard SQL problems involving complex deduplication and analytics, PySpark coding for production pipeline scenarios, and system design questions specific to streaming data infrastructure. The difficulty comes from the practical, scale-focused nature rather than abstract algorithmic puzzles.
Yes, Netflix Culture Principles questions appear in every interview round alongside technical questions, rather than being confined to a separate behavioral round. You'll be assessed on values like Freedom and Responsibility throughout the process, so prepare examples that demonstrate how you embody Netflix's culture while solving technical challenges.
For SQL, expect medium-hard problems using Spark SQL/Trino/Presto with window functions like ROW_NUMBER for deduplication and LAG/LEAD for sessionization, plus complex CTEs and event_id deduplication for metrics like daily active streamers. For Python, focus on PySpark DataFrame transformations, partition optimization, and handling late-arriving data at scale—no traditional algorithm practice needed.
This page shows you what the Netflix Data Engineer interview looks like in general. Your personalized report shows you how to prepare specifically — using your resume, a real job description, and Netflix's actual evaluation criteria.
This page shows every Netflix DE candidate the same thing. Your report is built around you — your resume, your gaps, your most likely questions.
What's inside: your fit score broken down by skill, experience, and culture; your top 3 risk areas by name; the 12 questions most likely for your specific background with full answer decodes; your experiences mapped to the Netflix Culture Principles you'll face; scripts for when they probe your weakest spots; sharp questions to ask your interviewers; and a one-page cheat sheet to review before you walk in. 55 pages. Delivered within 24 hours.
Within 24 hours. Your report is reviewed and delivered to your inbox within 24 hours of payment. Most orders arrive significantly faster. You'll receive an email with your personalized PDF as soon as it's ready.
30-day money-back guarantee, no questions asked. If your report doesn't help you feel more prepared, email us and we'll refund in full.